深入探秘大数据 Spark 的数据处理奥秘
大数据 Spark 已成为当今数据处理领域的关键技术,它的强大功能和高效性能使其在众多应用场景中发挥着重要作用。
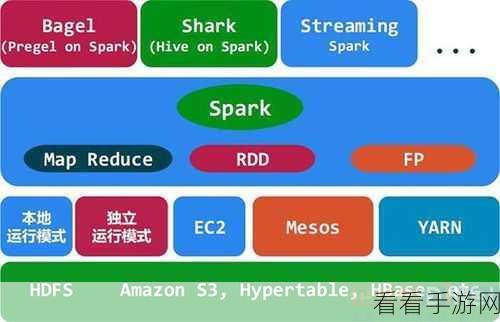
Spark 数据处理流程具有独特的特点和优势,其核心在于能够快速处理大规模的数据,并提供灵活的编程模型。
Spark 数据处理的第一步是数据摄入,这包括从各种数据源,如文件系统、数据库、网络等获取数据,并将其转化为 Spark 能够处理的格式,在这个阶段,数据的质量和准确性至关重要,需要进行必要的清洗和预处理。
接下来是数据转换,这是对摄入的数据进行各种操作,如过滤、聚合、映射、排序等,以满足具体的业务需求,通过巧妙地运用 Spark 的转换操作,可以将原始数据转化为有价值的信息。
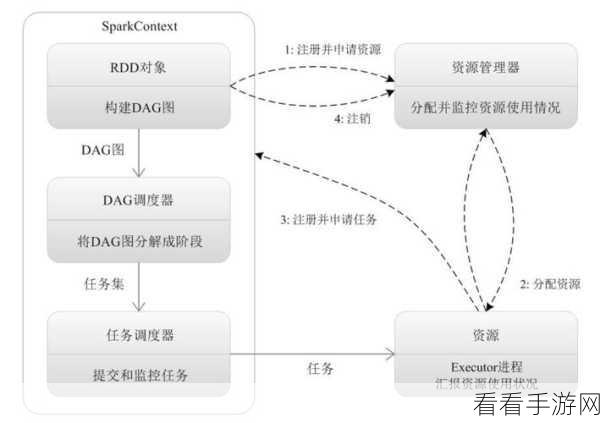
然后是数据存储,处理后的数据需要妥善保存,以便后续的查询和分析,Spark 支持多种存储方式,如内存、硬盘、分布式文件系统等,用户可以根据实际情况选择最适合的存储方案。
数据输出,将处理和存储好的数据以用户期望的形式输出,例如生成报表、写入数据库、发送到其他系统等。
在实际应用中,要充分发挥 Spark 数据处理的优势,还需要合理配置资源、优化算法和代码,并结合具体的业务场景进行定制化开发。
深入理解和掌握大数据 Spark 的数据处理流程,对于提升数据处理能力和实现业务价值具有重要意义。
文章参考来源:相关大数据技术书籍及专业论文。
