深入探秘大数据 Spark 开发与维护的关键技巧
大数据 Spark 已成为当今信息技术领域的重要组成部分,其开发和维护工作至关重要。
Spark 是一个强大的分布式计算框架,在处理大规模数据时表现出色,它具有高效的内存计算能力,能够快速处理海量数据,并提供丰富的 API 和工具,方便开发者进行各种复杂的数据处理任务。

要进行 Spark 的开发,首先需要熟悉其核心概念和架构,了解 Spark 的核心组件,如 SparkContext、RDD(弹性分布式数据集)等,是开发的基础,掌握 Spark 的编程模型,如使用 Scala、Python 或 Java 进行编程,也是必不可少的。
在维护方面,监控和优化 Spark 应用的性能是关键,需要关注资源使用情况、任务执行时间、数据倾斜等问题,并采取相应的优化措施,如调整并行度、使用合适的缓存策略等。
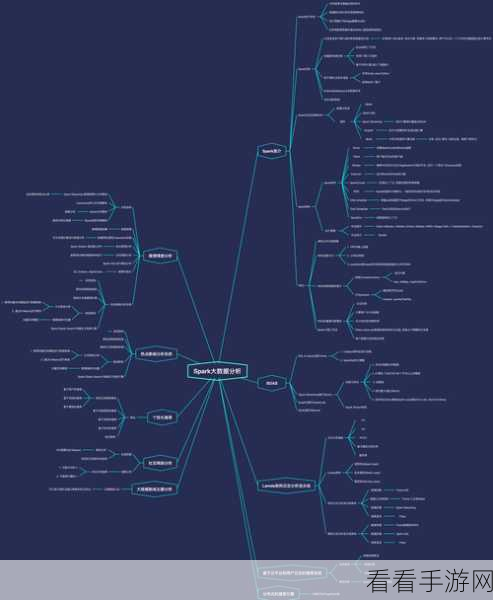
确保 Spark 集群的稳定性也是维护工作的重要任务,定期进行硬件和软件的检查和更新,合理配置资源,以及制定备份和恢复策略,都能有效提高集群的可靠性。
大数据 Spark 的开发和维护需要综合考虑多方面的因素,不断学习和实践,才能充分发挥其优势,为数据处理和分析提供强大的支持。
参考来源:相关技术文档及行业研究报告。
