掌握 C UnicodeEncoding 的精确之道
在编程的世界里,C# UnicodeEncoding 是一个十分重要的概念,若能准确运用,将为开发工作带来诸多便利。
C# UnicodeEncoding 涉及到字符编码的处理,其准确性对于程序的正确性和稳定性至关重要,在处理多语言文本、网络通信以及文件读写等场景中,正确使用 UnicodeEncoding 能够确保信息的准确传递和存储。
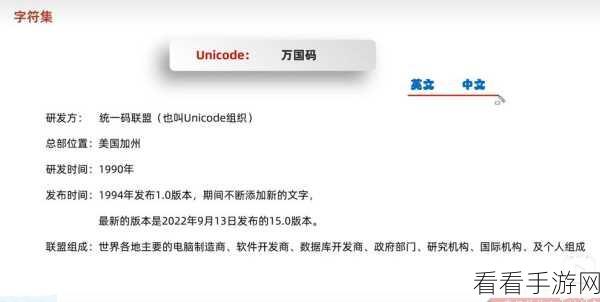
要实现 C# UnicodeEncoding 的准确运用,首先需要深入理解其基本原理,Unicode 是一种国际字符编码标准,它涵盖了世界上几乎所有的字符,而 C# 中的 UnicodeEncoding 类则提供了对 Unicode 字符的编码和解码操作。
要注意选择合适的编码方式,C# 中常见的 UnicodeEncoding 方式有 UTF-8、UTF-16 等,不同的编码方式在存储空间和处理效率上可能存在差异,需要根据具体的应用场景进行选择。

在实际编程中,还需要注意处理编码转换时可能出现的异常情况,当输入的字符无法按照指定的编码方式进行转换时,程序应该能够妥善处理这种异常,避免出现崩溃或错误的结果。
为了更好地掌握 C# UnicodeEncoding 的准确性,建议开发者多进行实践和测试,通过实际的项目开发,积累经验,不断优化编码处理的方式和方法。
C# UnicodeEncoding 的准确运用并非一蹴而就,需要开发者不断学习和探索,才能在实际开发中得心应手,确保程序的高质量运行。
文章参考来源:相关编程技术文档及个人编程经验总结。
