探秘大数据,Spark 与 Hadoop 的完美集成之道
在当今数字化的时代,大数据技术的应用愈发广泛和深入,Spark 和 Hadoop 的集成成为了众多开发者和企业关注的焦点。
Spark 作为一种快速、通用的大数据处理框架,具有出色的计算性能和丰富的功能,而 Hadoop 则以其强大的分布式存储能力和成熟的生态系统而闻名,将两者集成,可以充分发挥它们各自的优势,实现更高效、更强大的数据处理和分析。
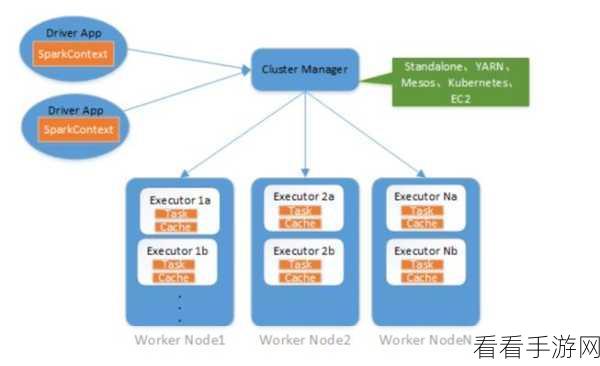
如何实现 Spark 和 Hadoop 的集成呢?需要了解两者的架构和工作原理,Spark 基于内存计算,能够快速处理大规模数据;Hadoop 则通过分布式文件系统(HDFS)实现数据的存储和管理,在集成过程中,要确保两者的版本兼容性,选择合适的集成方式。
配置环境也是至关重要的一步,需要正确安装和配置 Hadoop 集群,包括 NameNode、DataNode 等组件,并确保其正常运行,安装 Spark 并进行相关的配置,使其能够与 Hadoop 进行通信和数据交互。

数据的迁移和转换也是集成中的关键环节,要将数据从 Hadoop 的 HDFS 中读取到 Spark 中进行处理,需要使用合适的 API 和工具,要注意数据格式的转换和处理,以确保数据的准确性和完整性。
在实际的集成过程中,还可能会遇到各种问题和挑战,性能优化、资源管理、错误处理等,针对这些问题,需要不断地进行调试和优化,寻找最佳的解决方案。
Spark 和 Hadoop 的集成是一个复杂但充满价值的过程,通过合理的规划、配置和调试,可以实现两者的无缝集成,为大数据处理和分析带来更强大的支持。
参考来源:相关大数据技术文档及行业实践经验。
