在当今大数据时代,Hive 和 Spark 作为重要的数据处理工具,它们之间的数据整合显得至关重要,掌握有效的整合方法,能够极大地提升数据处理效率和质量。
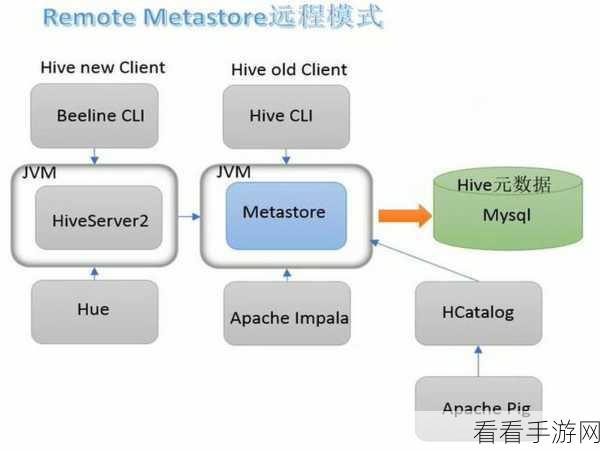
Hive 与 Spark 数据整合并非易事,需要深入理解两者的特性和工作机制,Hive 是基于 Hadoop 的数据仓库工具,擅长处理大规模的结构化数据;而 Spark 则是一种快速通用的计算引擎,具有出色的内存计算能力。
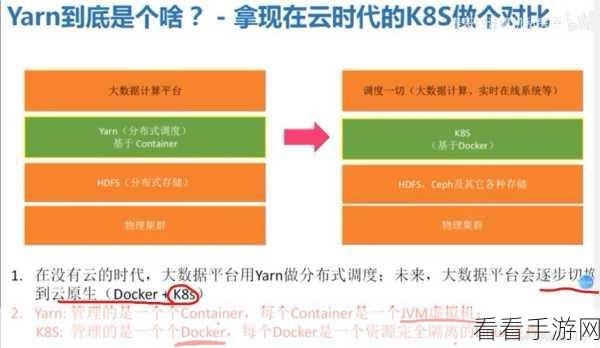
要实现 Hive 与 Spark 数据整合,关键在于数据的迁移和转换,这包括将 Hive 中的数据导入到 Spark 中进行处理,或者将 Spark 处理后的数据保存到 Hive 中以供后续使用,在数据迁移过程中,需要注意数据格式的兼容性和数据类型的匹配。
合理利用两者的 API 也是成功整合的关键,Hive 和 Spark 都提供了丰富的 API 接口,通过调用这些接口,可以实现数据的读取、写入和转换操作,还需要对数据的分区和分布进行合理规划,以提高数据处理的并行度和性能。
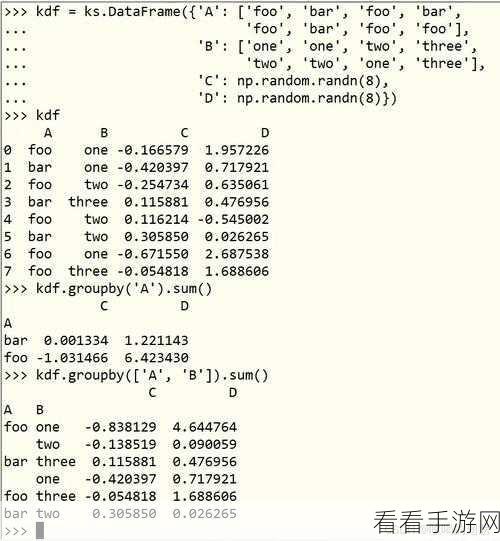
在实际应用中,还需要根据具体的业务需求和数据特点选择合适的数据整合方案,对于实时性要求较高的业务,可以采用 Spark Streaming 结合 Hive 的方式进行数据整合;而对于大规模的离线数据处理,则可以使用 Spark SQL 与 Hive 进行深度融合。
Hive 与 Spark 的数据整合是一个复杂但充满挑战和机遇的领域,只有不断探索和实践,才能找到最适合自己业务场景的数据整合方法,从而充分发挥两者的优势,为企业的数据分析和决策提供有力支持。
文章参考来源:大数据技术相关书籍及专业论坛交流。