破解 Kafka 消费模型中消息顺序处理难题
Kafka 消费模型中的消息顺序处理一直是技术领域的关键问题,在当今数字化时代,数据的准确传递和有序处理至关重要,而 Kafka 作为一种广泛应用的分布式消息系统,其消费模型对于消息顺序的处理方式直接影响着系统的性能和稳定性。
要理解 Kafka 消费模型如何处理消息顺序,首先需要明晰 Kafka 本身的架构和工作原理,Kafka 采用分区的方式存储消息,每个分区都是一个有序的消息队列,但在实际的消费过程中,由于消费者的数量和消费方式的不同,可能会导致消息顺序的混乱。
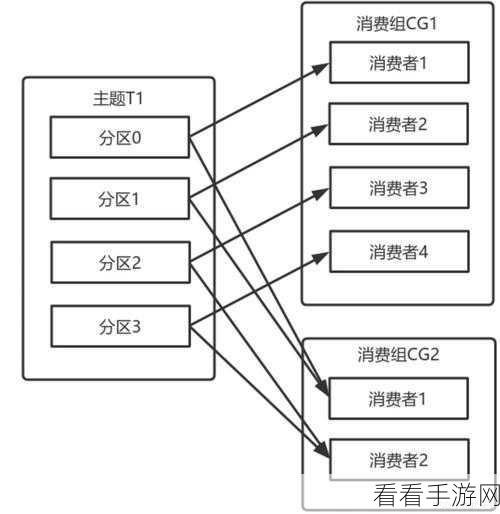
为了有效处理消息顺序,Kafka 提供了一些机制和策略,关键的一点是对消费者组的合理配置,通过将消费者分配到不同的分区,并且确保同一分区内的消息只能被一个消费者处理,可以在一定程度上保证消息的顺序性。
Kafka 还支持设置消息的 key 值,通过为消息设置具有唯一性和有序性的 key 值,可以让 Kafka 更好地对消息进行排序和处理。
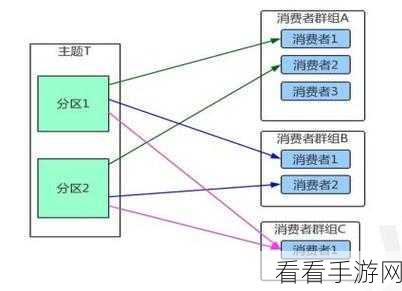
在实际应用中,还需要考虑网络延迟、消息丢失等因素对消息顺序处理的影响,这就要求开发者在设计和实现系统时,充分考虑各种可能的异常情况,并采取相应的容错和恢复机制。
处理 Kafka 消费模型中的消息顺序并非一蹴而就,需要综合考虑多种因素,并运用合理的配置和策略,只有这样,才能确保系统在高效运行的同时,保证消息顺序的准确性。
文章参考来源:相关技术文档及实践经验总结。
