探秘 Kafka 消费模型的负载均衡之道
Kafka 消费模型中的负载均衡是一个关键且复杂的问题,在当今数字化的时代,数据处理的高效性和稳定性至关重要,而 Kafka 作为一种强大的分布式消息队列,其消费模型的负载均衡策略直接影响着系统的性能和可靠性。
要理解 Kafka 消费模型的负载均衡,首先得清楚什么是负载均衡,负载均衡简单来说,就是将工作任务均匀地分配到多个处理单元上,以避免某些单元负载过重,而另一些单元却闲置的情况,在 Kafka 中,这意味着要确保各个消费者能够公平、有效地获取和处理消息,从而实现系统的最优性能。
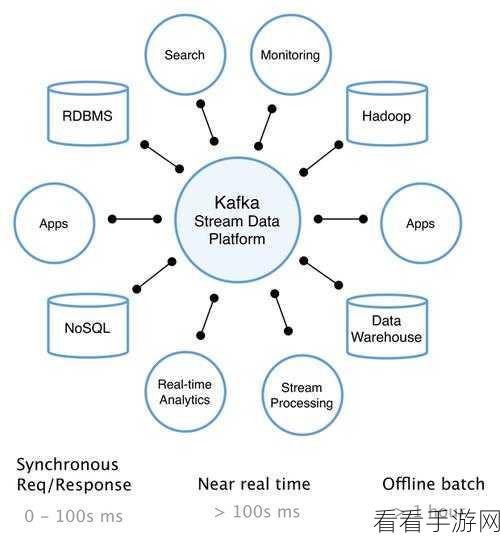
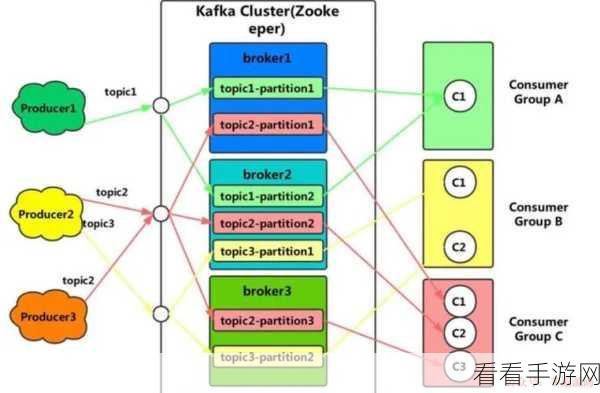
Kafka 消费模型的负载均衡策略主要基于分区分配机制,分区是 Kafka 存储消息的基本单位,而消费者组则是一组共同消费主题的消费者集合,当消费者组中的消费者数量发生变化,或者新的主题和分区被创建时,Kafka 会重新进行分区分配,以实现负载的均衡。
实现负载均衡的过程中,Kafka 采用了多种算法和策略,常见的有轮询分配、范围分配和粘性分配等,轮询分配是最简单的方式,它依次将分区分配给消费者;范围分配则根据分区的范围进行分配;粘性分配则在一定程度上考虑了之前的分配结果,以减少重新分配的频率。
要实现理想的负载均衡并非一帆风顺,可能会遇到诸如网络延迟、消费者处理能力差异、消息量不均衡等问题,为了解决这些问题,需要对系统进行精细的配置和监控。
可以通过调整消费者的数量和处理能力,使其与消息的产生速率相匹配;利用监控工具实时监测负载情况,及时发现并解决负载不均衡的问题;还可以根据业务需求,对分区策略进行优化和定制。
深入理解和掌握 Kafka 消费模型的负载均衡,对于构建高效、稳定的分布式消息处理系统具有重要意义,只有不断探索和优化,才能充分发挥 Kafka 的强大功能,满足日益复杂的业务需求。
文章参考来源:相关技术文档及个人实践经验总结。
