探秘 Kafka 消费模型,自动提交偏移量的技巧与策略
Kafka 消费模型中的自动提交偏移量是一个关键环节,它直接影响着数据处理的准确性和效率,在实际应用中,掌握正确的方法来处理自动提交偏移量至关重要。
要理解 Kafka 消费模型中的自动提交偏移量,首先需要明确其基本概念和作用,偏移量是用于记录消费者在分区中的消费位置,而自动提交偏移量则是让系统按照一定的规则自动更新这个位置记录。
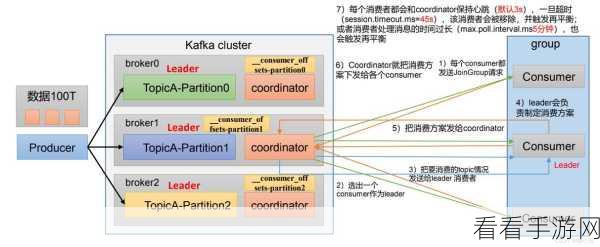
如何实现有效的自动提交偏移量呢?这需要综合考虑多个因素,配置合适的提交间隔是重要的一点,提交间隔过短可能导致频繁的提交操作,增加系统开销;而提交间隔过长则可能在出现故障时导致数据重复处理或丢失。
还需要关注消费者的处理能力,如果消费者处理消息的速度较慢,而自动提交偏移量的频率过高,就可能出现还未处理完的消息被标记为已处理的情况。
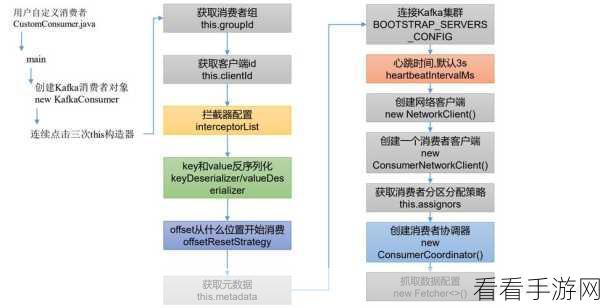
在实际操作中,还可以结合监控和日志来及时发现自动提交偏移量过程中可能出现的问题,通过对监控数据的分析,能够了解偏移量提交的情况,及时调整相关配置,以确保系统的稳定运行。
深入了解和掌握 Kafka 消费模型中自动提交偏移量的机制,合理配置相关参数,并结合有效的监控手段,才能使 Kafka 系统在数据处理中发挥出最佳性能。
参考来源:相关技术文档及实践经验总结。
