探秘 Kafka 消费模型的分区分配策略
Kafka 消费模型中的分区分配,一直是技术领域备受关注的重要课题,在分布式系统中,合理的分区分配能够极大地提升数据处理的效率和系统的稳定性。
Kafka 作为一种高性能的分布式消息队列,其分区分配机制的理解和应用至关重要,分区分配的优劣直接影响到消息的消费速度、系统的负载均衡以及数据的可靠性。
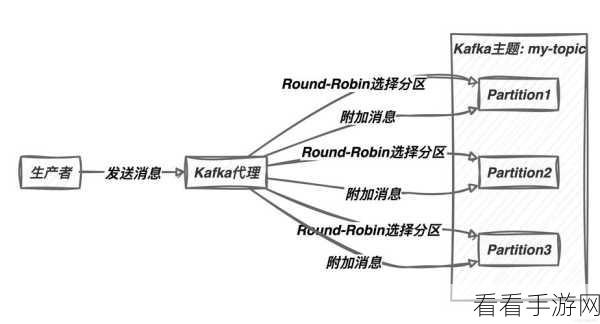
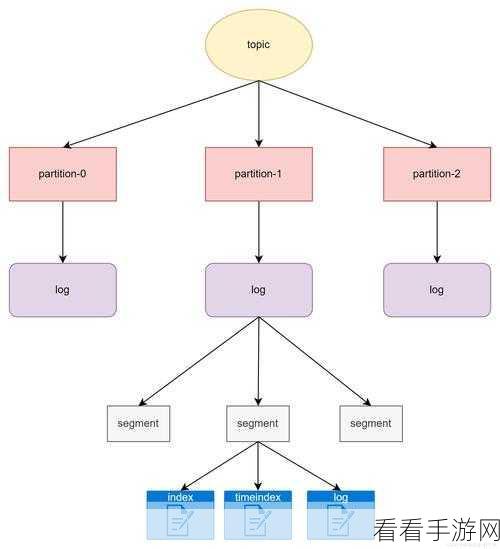
要深入理解 Kafka 消费模型的分区分配,首先需要了解其基本原理,Kafka 中的分区是消息存储和传输的基本单位,每个分区都可以在不同的节点上进行存储和处理,而分区分配则是决定哪些消费者能够消费哪些分区的过程。
在分配策略方面,Kafka 提供了多种方式,常见的有轮询分配、范围分配和粘性分配等,轮询分配是将分区依次分配给消费者,以实现较为平均的负载分布;范围分配则是根据分区的编号范围来进行分配,适用于某些特定的场景;粘性分配则在一定程度上考虑了消费者已经分配的分区,以减少分配的变动频率。
对于开发者和运维人员来说,选择合适的分区分配策略需要综合考虑多种因素,系统的负载情况、消费者的处理能力、消息的重要性和时效性等等,如果系统负载较高,可能需要采用更灵活的分配策略,以避免某些节点过载;而对于处理能力差异较大的消费者,可能需要根据其能力进行有针对性的分配。
还需要关注分区分配的动态调整,随着系统的运行和负载的变化,适时地调整分区分配能够更好地适应实际情况,这需要对系统的状态进行实时监控,并通过相应的算法和机制来实现。
深入掌握 Kafka 消费模型的分区分配,对于构建高效、稳定的分布式系统具有重要意义,不断的实践和探索,结合具体的业务需求和系统特点,才能找到最适合的分区分配方案。
文章参考来源:相关技术文档及实践经验总结。
