掌控 Hive Shuffle 性能优化的秘籍大公开
Hive Shuffle 性能的优化是提升数据分析效率的关键所在,在大数据处理中,Hive Shuffle 环节常常成为性能瓶颈,若能对其进行有效调优,将极大提高数据处理的速度和质量。
要理解 Hive Shuffle 的性能调优,首先得清楚什么是 Shuffle 过程,Shuffle 简单来说就是将具有相同键值的记录分发到同一个 Reduce 任务中进行处理,这个过程涉及数据的分区、排序和分发,如果处理不当,会导致大量的数据传输和磁盘 I/O 操作,从而影响性能。
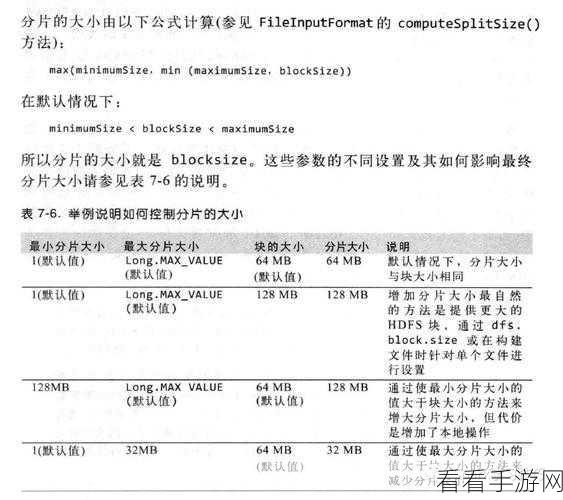
优化 Hive Shuffle 性能的方法众多,合理设置 Map 和 Reduce 的数量至关重要,Map 任务数量过少,可能导致单个 Map 处理的数据量过大,增加处理时间;而 Reduce 任务数量过多或过少,都会影响数据的分发和聚合效率,需要根据数据量和计算资源来合理调整这两个参数。
数据的分区策略也对性能有着显著影响,选择合适的分区字段,能够使数据在 Shuffle 过程中更加均匀地分布到不同的 Reduce 任务中,避免某些 Reduce 任务负载过重,调整分区的数量和大小,可以进一步优化数据的分发效果。
压缩数据也是一种有效的优化手段,在 Shuffle 过程中,对传输的数据进行压缩,可以减少数据量,降低网络传输开销和磁盘 I/O 操作,常见的压缩格式如 Snappy、LZO 等,都能在保证一定压缩比的同时,提供较好的压缩和解压性能。
在实际应用中,还需要结合具体的业务场景和数据特点,综合运用上述方法,并不断进行测试和调整,以找到最适合的性能优化方案,只有不断探索和实践,才能真正掌控 Hive Shuffle 的性能,为大数据处理带来更高的效率和价值。
文章参考来源:大数据处理相关技术文档和实践经验总结。
