深度解析,Kafka 消费模型的消息缓存秘籍
Kafka 消费模型中的消息缓存机制一直是众多开发者关注的焦点,它在数据处理和系统性能优化方面起着至关重要的作用。
要理解 Kafka 消费模型的消息缓存,我们得先明确其基本概念,消息缓存是为了提高数据处理的效率,避免频繁的磁盘读写操作,从而实现更流畅的数据传输。
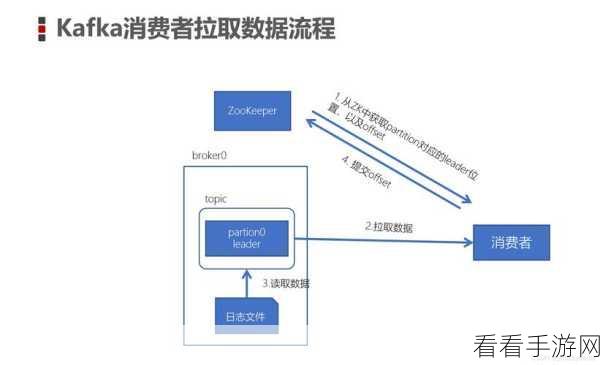
Kafka 消费模型的消息缓存具有一些显著特点,它能够根据系统的负载和资源情况,动态地调整缓存的大小,以达到最佳的性能表现,缓存中的消息会按照一定的规则进行排序和存储,方便消费者快速获取和处理。
在实际应用中,合理配置消息缓存参数至关重要,这包括设置缓存的容量、过期时间等,如果缓存容量过小,可能导致消息丢失或者处理延迟;而过大的缓存则可能占用过多的系统资源。
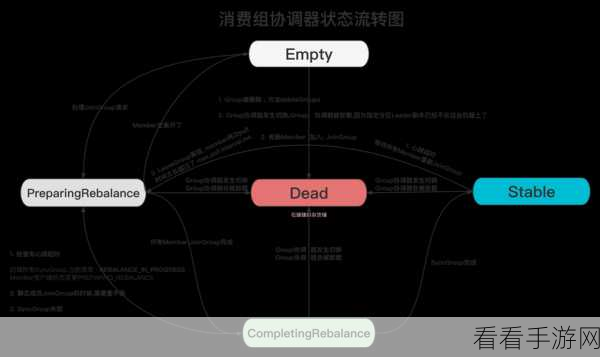
还需要考虑消息的写入和读取策略,写入时,要确保消息能够及时进入缓存并按照规则存储;读取时,要优化读取算法,提高读取效率。
为了实现更高效的消息缓存,开发者还可以结合其他技术和工具,使用分布式缓存系统来扩展缓存容量,或者利用监控工具实时监测缓存的使用情况。
深入掌握 Kafka 消费模型的消息缓存机制,对于优化系统性能、提高数据处理效率具有重要意义。
参考来源:相关技术文档及行业研究报告。
