探秘 Spark 函数,数据建模的神奇密码
Spark 函数在数据建模领域发挥着至关重要的作用,它能够帮助我们处理和分析海量的数据,从而为各种应用提供有力的支持。
要理解 Spark 函数如何进行数据建模,首先得清楚数据建模的基本概念,数据建模是创建数据结构和关系的过程,旨在更好地理解和管理数据。
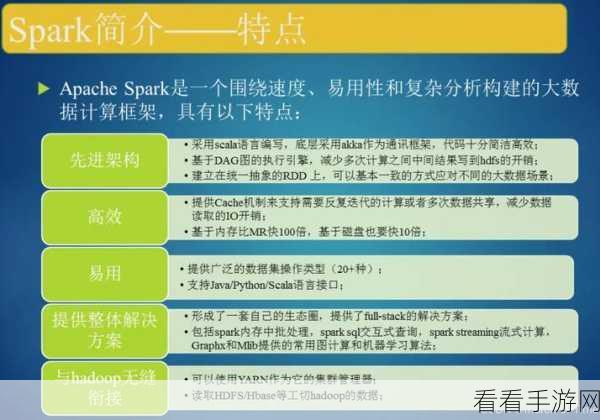
Spark 函数为数据建模带来了高效性和灵活性,其强大的并行计算能力,使得处理大规模数据变得轻松快捷,通过 Spark 的分布式计算框架,可以同时在多个节点上进行数据处理,大大缩短了处理时间。
在数据清洗方面,Spark 函数也表现出色,它能够去除重复数据、处理缺失值以及纠正错误数据,为后续的建模工作提供高质量的数据基础。
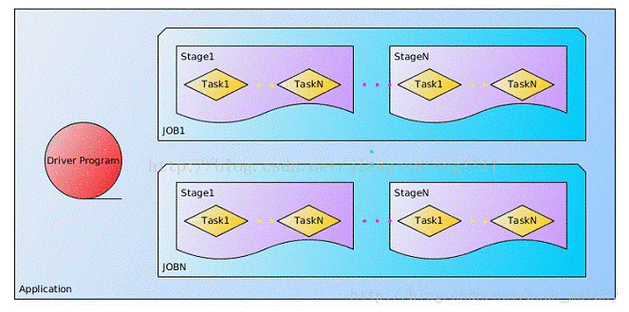
对于特征工程,Spark 函数提供了丰富的工具和方法,可以对数据进行特征提取、转换和选择,以找到最具代表性和相关性的特征,从而提高模型的准确性和性能。
在模型训练阶段,Spark 函数支持多种机器学习算法的实现,无论是分类问题还是回归问题,都能找到合适的算法进行建模。
在模型评估和优化方面,Spark 函数能够帮助我们对模型的性能进行准确评估,并根据评估结果进行优化调整。
掌握 Spark 函数进行数据建模的方法和技巧,对于数据科学家和相关从业者来说是必不可少的,不断学习和实践,才能更好地利用 Spark 函数在数据建模中发挥出巨大的价值。
文章参考来源:相关技术文档及专业书籍。
