掌握 Kafka C数据管理的秘诀
在当今数字化的时代,数据管理成为了各个领域的关键环节,对于使用 C#语言来处理 Kafka 数据的开发者来说,如何高效、准确地进行数据管理是一项重要的任务,让我们一同深入探索 Kafka C#数据管理的奥秘。
中心句:数据管理在当今时代至关重要,特别是对于使用 C#处理 Kafka 数据的开发者。
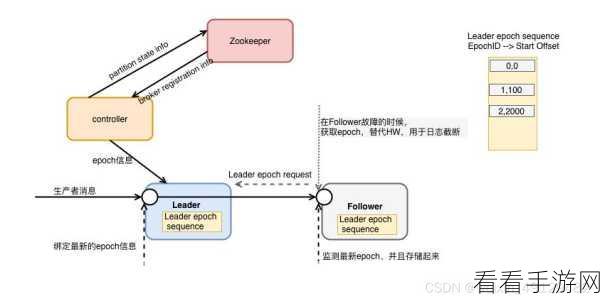
Kafka 作为一个分布式的消息队列系统,在处理大量数据的场景中表现出色,而 C#作为一种广泛应用的编程语言,为开发者提供了丰富的工具和方法来与 Kafka 进行交互和数据管理。
中心句:Kafka 是出色的分布式消息队列系统,C#为与 Kafka 交互提供丰富工具。
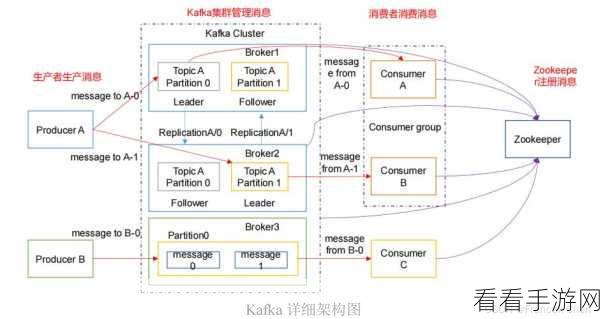
要实现有效的 Kafka C#数据管理,首先需要了解 Kafka 的基本原理和架构,明白其消息的发布与订阅机制,以及数据的存储和传输方式,这是后续进行数据管理的基础。
中心句:了解 Kafka 基本原理和架构是实现有效数据管理的基础。
选择合适的 C#库和工具是关键,Confluent.Kafka 是一个常用且功能强大的库,它提供了丰富的 API 来实现数据的生产和消费。
中心句:选择合适的 C#库和工具,如 Confluent.Kafka 至关重要。
在数据管理过程中,数据的序列化和反序列化也是不容忽视的环节,确保数据在传输和存储过程中的完整性和准确性,需要选择合适的序列化方式,如 JSON、ProtoBuf 等。
中心句:数据管理中数据的序列化和反序列化环节不容忽视。
错误处理和异常情况的应对也是必不可少的,在与 Kafka 交互时,可能会遇到网络问题、消息丢失等情况,提前做好错误处理机制能够保证系统的稳定性和可靠性。
中心句:错误处理和应对异常情况对保证系统稳定性和可靠性很必要。
进行性能优化也是提升数据管理效果的重要手段,通过调整缓冲区大小、优化消息发送和接收的频率等方式,可以提高系统的整体性能。
中心句:性能优化是提升数据管理效果的重要手段。
掌握 Kafka C#数据管理并非一蹴而就,需要开发者不断学习和实践,结合具体的业务需求,灵活运用各种技术和方法,才能实现高效、稳定的数据管理。
文章参考来源:相关技术文档及个人实践经验总结。
