探索 Kafka 消费模型的数据管理秘籍
Kafka 消费模型在数据管理领域发挥着重要作用,掌握其数据管理方法至关重要。
Kafka 作为一种强大的分布式消息系统,其消费模型的数据管理具有独特的特点和挑战。
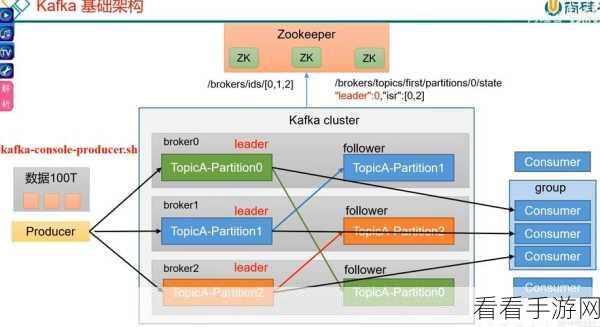
要理解 Kafka 消费模型的数据管理,我们得先搞清楚几个关键概念,首先是消费者组,它是一组协同消费主题分区的消费者实例,消费者组中的消费者可以根据分配策略共同处理主题的消息,其次是偏移量,它记录了消费者在每个分区中的消费位置。
在实际的数据管理中,我们需要关注数据的一致性和可靠性,为了确保数据的一致性,消费者在处理消息时要遵循一定的顺序和规则,在多线程处理消息时,要注意线程安全和数据同步,而对于数据的可靠性,我们可以通过配置合适的参数来实现,比如设置重试机制、确认机制等。
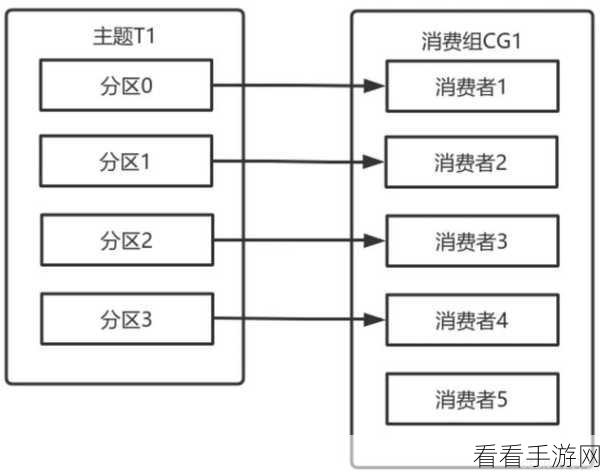
优化数据存储和读取也是数据管理的重要环节,可以根据业务需求调整分区数量和副本因子,以提高数据的存储效率和读取性能,合理利用缓存机制能够进一步提升数据处理的速度。
在监控和故障排查方面,我们要密切关注消费者的指标,如消费速率、偏移量等,通过这些指标,可以及时发现潜在的问题,并采取相应的措施进行解决。
要实现 Kafka 消费模型的高效数据管理,需要综合考虑多个方面,从概念理解到实际操作,从性能优化到监控排查,每个环节都不能忽视。
参考来源:相关技术文档和行业实践经验。
