Python 和 JS 爬虫性能提升秘籍大揭秘
爬虫技术在当今的互联网时代具有重要的作用,而 Python 和 JS 爬虫的性能优化更是备受关注。
想要提高 Python 和 JS 爬虫的性能,首先要确保代码的高效性,这意味着在编写爬虫代码时,需要遵循良好的编程习惯,减少冗余和不必要的计算,避免重复的请求和数据处理操作,合理利用缓存机制等。
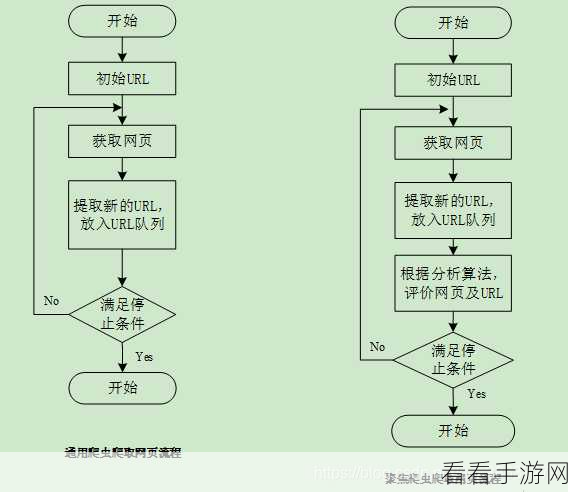
网络请求的优化也是关键的一环,选择合适的网络库和请求方式,能够显著提升爬虫的速度,设置合理的请求头和参数,避免被目标网站识别为爬虫并加以限制。
数据存储和处理的策略同样影响着爬虫性能,选择高效的数据结构和存储方式,能够加快数据的读写和分析速度,在处理大量数据时,还可以采用分布式计算或并行处理的技术,提高整体的效率。

对于反爬虫机制的应对也是必不可少的,了解目标网站的反爬虫策略,通过模拟正常用户行为、设置合理的请求间隔等方式,降低被封禁的风险,从而保障爬虫的稳定运行。
提高 Python 和 JS 爬虫性能需要综合考虑代码优化、网络请求、数据处理和反爬虫策略等多个方面,只有不断探索和实践,才能让爬虫更加高效地获取所需数据。
参考来源:个人经验总结及相关技术论坛交流
