掌握 Spark 函数,实现数据优化的秘籍
Spark 函数在数据处理中扮演着至关重要的角色,其数据优化能力更是决定着处理效率和效果。
想要实现高效的数据优化,深入理解 Spark 函数的特性和应用场景是关键。

我们得明确数据的特点和处理需求,不同类型、规模和结构的数据,适用的优化策略也各不相同,对于大规模的结构化数据,可能需要采用特定的分区策略和缓存机制;而对于非结构化数据,数据清洗和转换的方法就显得尤为重要。
接下来要合理配置资源,这包括内存、CPU 核心数等硬件资源的分配,以及 Spark 应用的并行度设置,通过合理的资源配置,可以充分发挥硬件性能,提升数据处理的速度。
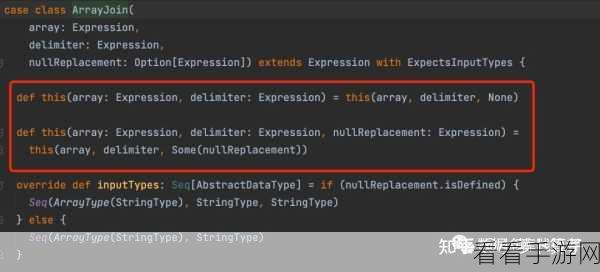
优化数据存储格式也不能忽视,选择合适的数据存储格式,如 Parquet、ORC 等,可以减少数据存储空间,提高读取和写入的效率。
优化代码逻辑也是必不可少的环节,避免不必要的计算和重复操作,精简代码结构,能够显著提高程序的执行效率。
在实际应用中,还需要不断进行测试和调优,通过监控性能指标,如处理时间、内存使用等,发现潜在的问题并及时调整优化策略。
掌握 Spark 函数进行数据优化并非一蹴而就,需要综合考虑多个方面,并结合实际情况不断探索和改进。
文章参考来源:相关技术文档及实践经验总结。
