深度解析,Kafka 幂等性的数据优化秘籍
Kafka 幂等性在数据处理中扮演着至关重要的角色,合理进行数据优化能够显著提升系统性能和稳定性。
Kafka 幂等性的实现机制是保障数据准确处理的关键,它通过为每条消息赋予唯一的标识,确保相同的消息在多次发送时只被处理一次,有效避免了数据重复和不一致的问题。
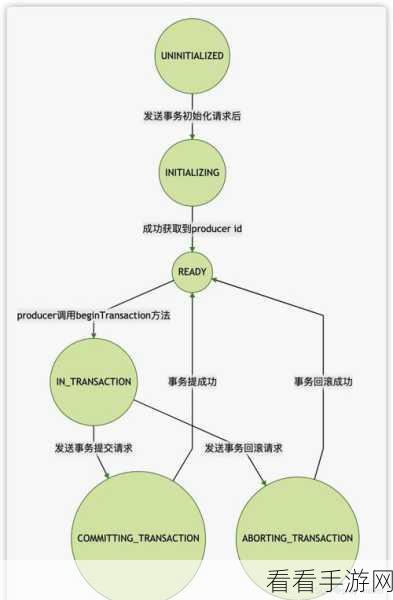
要优化 Kafka 幂等性的数据处理,需要从多个方面入手,对于消息的发送端,要确保生成的唯一标识具有足够的随机性和唯一性,避免出现重复标识导致的处理错误,在接收端,要建立有效的消息去重机制,快速识别并过滤掉重复的消息,提高数据处理的效率,还需要对消息的存储和读取进行优化,合理配置存储资源,提高数据的读写速度。
在实际应用中,还需要根据具体的业务场景和数据特点,灵活调整幂等性的相关参数和策略,对于数据量较大、实时性要求较高的场景,可以采用更高效的去重算法和存储方式;而对于数据准确性要求极高的场景,则需要更加严格的消息校验和处理机制。

深入理解 Kafka 幂等性的原理和机制,并结合实际业务需求进行针对性的优化,才能充分发挥其在数据处理中的优势,为系统的稳定运行和高效处理提供有力保障。
参考来源:相关技术文档及实践经验总结。
