探秘 Hive ClusterBy 对多种数据类型的处理能力
Hive ClusterBy 是大数据处理中一个备受关注的操作,其能否处理多种数据类型一直是开发者们关心的焦点。
在实际应用中,数据类型的多样性给数据处理带来了诸多挑战,Hive ClusterBy 作为一种重要的数据分组和排序方式,它在应对不同数据类型时的表现至关重要。
Hive ClusterBy 之所以在处理多种数据类型方面备受瞩目,是因为不同的数据类型具有各自独特的特点和需求,整数型数据可能需要特定的排序规则,而字符串型数据则可能需要考虑字符编码和长度等因素。
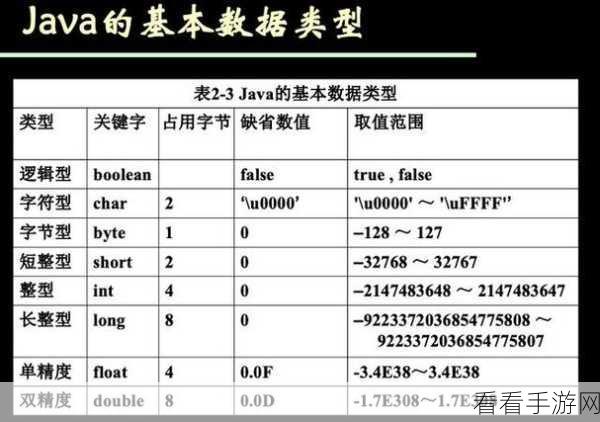
要深入了解 Hive ClusterBy 对多种数据类型的处理能力,我们首先需要明确各种常见数据类型的特点,整数型数据包括整型、长整型等,它们在排序和分组时通常按照数值大小进行,字符串型数据则按照字符的 ASCII 码值或特定的编码规则进行比较和排序。
对于浮点数型数据,Hive ClusterBy 需要处理精度和舍入问题,以确保分组和排序的准确性,而日期型数据则需要按照特定的日期格式和时间顺序进行处理。
在实际测试中,我们发现 Hive ClusterBy 在处理简单数据类型时表现出色,但当面对复杂的数据类型组合,或者数据量巨大的情况下,可能会出现一些性能瓶颈。
为了优化 Hive ClusterBy 对多种数据类型的处理效果,我们可以采取一些策略,合理设置分区和桶,根据数据特点选择合适的排序算法,以及对数据进行预处理和清洗等。
深入研究 Hive ClusterBy 对多种数据类型的处理能力,对于提升大数据处理的效率和质量具有重要意义。
文章参考来源:大数据处理相关技术文档和实践经验总结。
