破解 Hive SQL 处理大数据的神秘密码
Hive SQL 是处理大数据的有力工具,但很多人在使用时会遇到各种难题,如何才能巧妙地运用 Hive SQL 来处理大数据呢?
Hive SQL 之所以在大数据处理中占据重要地位,是因为其强大的功能和高效的性能,它能够轻松应对海量数据的存储、查询和分析,为企业和开发者提供了极大的便利。
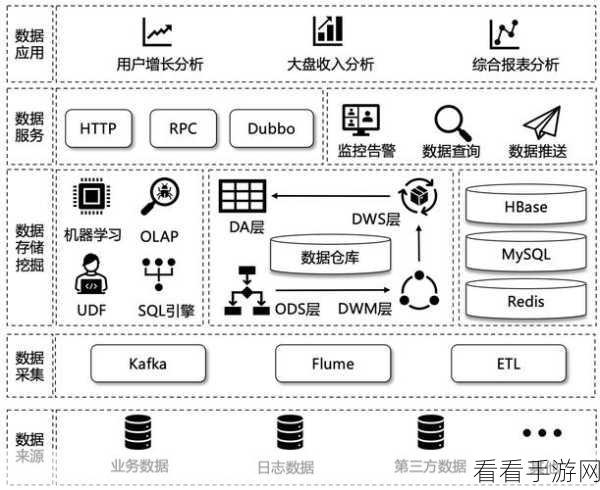
要熟练运用 Hive SQL 处理大数据,优化查询语句是关键,合理地构建索引、选择合适的分区方式以及巧妙地运用聚合函数,都能显著提高查询的效率,在处理大规模数据时,根据数据的特点选择合适的索引类型,可以大大减少查询的时间成本。
数据存储的策略也不容忽视,了解不同的数据存储格式,如 Parquet、ORC 等,并根据数据的特点和访问模式进行选择,能够有效提升数据的读写性能。
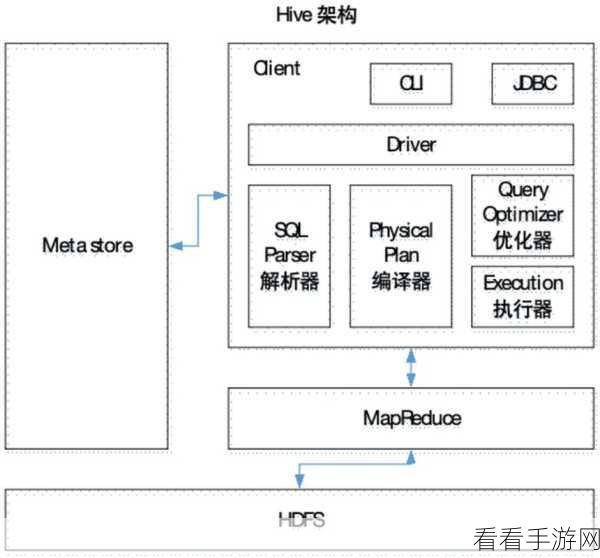
掌握 Hive SQL 的高级特性也是必不可少的,动态分区、窗口函数等功能,能够满足更复杂的数据分析需求,为挖掘数据的潜在价值提供有力支持。
在实际应用中,还需要不断地进行性能测试和调优,通过监控系统资源的使用情况,及时发现并解决可能存在的性能瓶颈,确保 Hive SQL 在处理大数据时始终保持高效稳定的运行。
想要精通 Hive SQL 处理大数据,不仅需要深入理解其原理和特性,还需要在实践中不断积累经验,探索适合不同场景的最佳解决方案。
文章参考来源:相关技术文档及行业经验总结。
