探秘 Kafka 消费模型的数据整合之道
Kafka 消费模型的数据整合,是众多开发者和数据处理人员关注的重点领域,它在现代数据处理架构中扮演着至关重要的角色,直接影响着数据的准确性和及时性。
要理解 Kafka 消费模型的数据整合,首先得清楚 Kafka 本身的工作原理,Kafka 是一种分布式的消息队列系统,它具有高吞吐量、低延迟和可扩展性等优点,在数据整合过程中,其独特的消息存储和传递机制为高效处理提供了基础。
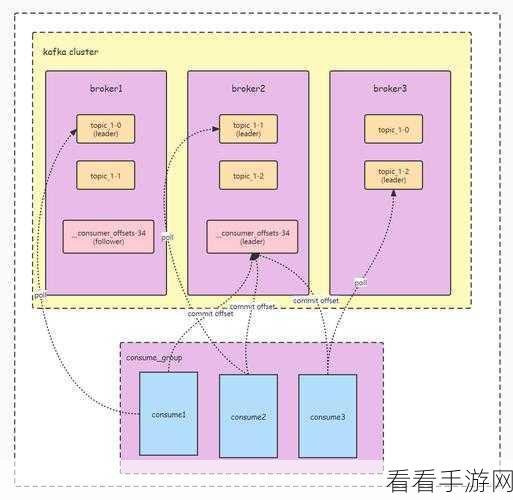
数据整合的关键在于如何有效地从 Kafka 中消费数据,并将其与其他数据源进行融合,这需要考虑数据格式的转换、数据清洗、数据关联等多个环节,对于不同格式的数据,需要通过特定的转换工具或算法将其统一为可处理的标准格式。
数据清洗也是必不可少的步骤,这包括去除重复数据、纠正错误数据、过滤无效数据等,以确保整合后的数据质量。
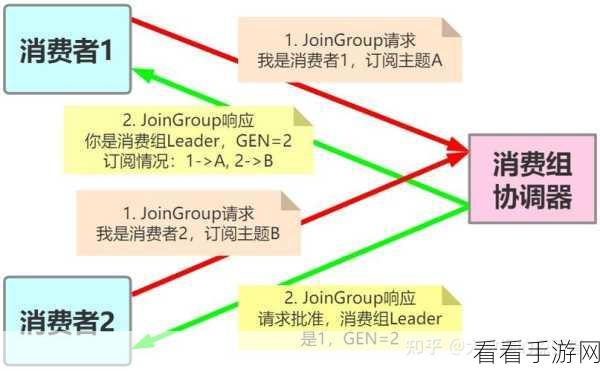
在数据关联方面,要根据业务需求和数据特点,确定合适的关联字段和关联方式,将来自不同数据源的数据有机地结合起来。
为了实现高效的数据整合,还需要合理配置 Kafka 的消费者参数,如消费组的设置、消费速率的控制等。
Kafka 消费模型的数据整合是一个复杂但充满挑战和机遇的领域,只有深入理解其原理和方法,并结合实际业务需求进行优化和创新,才能实现高效、准确的数据整合,为企业的决策和业务发展提供有力支持。
参考来源:相关技术文档及行业研究报告。
