深入探究,Spark SortBy 数据归档的精妙之道
在当今数字化的时代,数据处理和管理成为了至关重要的任务,Spark 作为一款强大的大数据处理框架,其中的 SortBy 操作在数据归档方面有着独特的应用,本文将深入探讨 Spark SortBy 如何进行数据归档,为您揭开这一神秘面纱。
中心句:Spark 作为大数据处理框架,SortBy 操作在数据归档方面有独特应用。
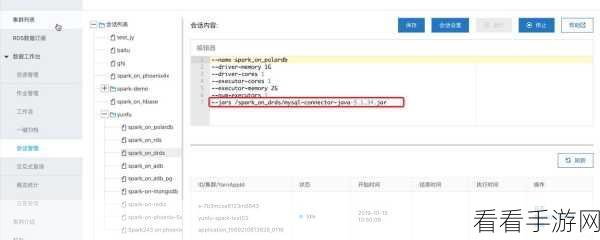
Spark SortBy 是一种在 Spark 中用于对数据进行排序的操作,它能够根据指定的键对数据进行排序,这为数据归档提供了基础,通过合理地设置排序键和排序规则,可以将数据按照一定的顺序进行整理,从而更便于后续的归档操作。
中心句:Spark SortBy 能根据指定键对数据排序,为数据归档提供基础。
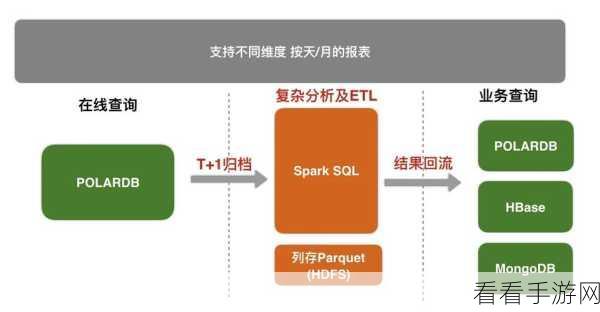
在进行数据归档时,首先需要明确归档的目标和需求,是要按照时间顺序归档,还是按照数据的某个特定属性进行归档?明确目标后,就可以针对性地设置 SortBy 的参数,如果要按照时间戳进行归档,可以将时间戳作为排序键,并选择升序或降序排列。
中心句:进行数据归档先明确目标和需求,针对性设置 SortBy 参数。
还需要考虑数据量的大小和处理的性能,对于大规模的数据,可能需要采用分布式的处理方式来提高效率,可以调整 Spark 的配置参数,如内存分配、并行度等,以确保数据归档的过程能够高效稳定地进行。
中心句:考虑数据量和处理性能,采用分布式处理方式并调整 Spark 配置参数。
数据的格式也会对归档产生影响,不同的格式可能需要不同的处理方式和工具,对于结构化的数据,可以使用 Spark 的 DataFrame 进行处理;而对于非结构化的数据,则可能需要进行额外的转换和预处理。
中心句:数据格式影响归档,不同格式需不同处理方式和工具。
Spark SortBy 在数据归档中发挥着重要作用,但要实现高效、准确的数据归档,需要综合考虑多方面的因素,并根据实际情况进行灵活的配置和优化,希望本文能够为您在使用 Spark SortBy 进行数据归档时提供有益的参考和帮助。
参考来源:相关技术文档及实践经验总结
