Hive 与 Spark 切换秘籍,实战指南大揭秘
在当今的大数据处理领域,Hive 和 Spark 是两款备受瞩目的工具,掌握在它们之间的切换技巧,对于提升数据处理效率和优化工作流程至关重要。
Hive 凭借其强大的 SQL 兼容性和成熟的生态系统,在数据仓库领域有着广泛的应用,而 Spark 则以其出色的内存计算能力和高效的执行引擎,在实时处理和复杂计算场景中表现卓越。
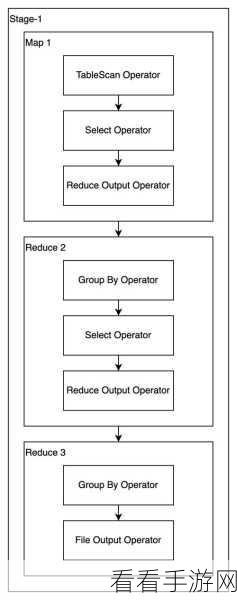
如何实现 Hive 和 Spark 之间的无缝切换呢?
第一步,深入了解两者的特性和适用场景,Hive 适合处理大规模的批处理任务,对于复杂的查询和数据聚合操作具有良好的支持,而 Spark 则在处理实时数据、迭代计算和机器学习任务方面更具优势。
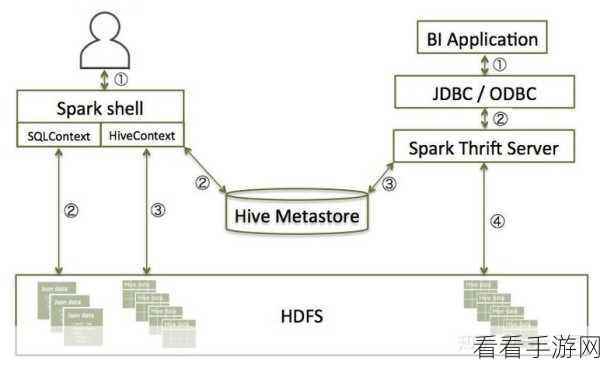
第二步,熟悉两者的数据格式和存储方式,Hive 通常与 HDFS 紧密结合,数据以表的形式存储,Spark 则支持多种数据源,包括 HDFS、S3 等,并且可以处理不同格式的数据,如 Parquet、JSON 等。
第三步,掌握切换的时机和策略,当面临数据量巨大、计算复杂度高的任务时,如果对实时性要求不高,可以选择 Hive 进行批处理,而对于需要快速响应和实时处理的场景,Spark 则是更好的选择。
第四步,优化配置和参数设置,在切换过程中,根据具体的任务需求和硬件环境,合理调整 Hive 和 Spark 的配置参数,以达到最佳的性能表现。
要在 Hive 和 Spark 之间实现灵活切换,需要对它们的特点有清晰的认识,结合实际业务需求和数据特点,选择合适的工具,并进行有效的配置和优化。
文章参考来源:大数据处理相关技术文档和实践经验总结。
