深入探究,Kafka 幂等性的数据归档秘籍
Kafka 幂等性在数据处理中发挥着重要作用,而数据归档更是其中关键的一环。
要理解 Kafka 幂等性的数据归档,我们先来看看什么是幂等性,幂等性意味着对同一操作进行多次执行所产生的结果与执行一次的结果相同,在 Kafka 中,幂等性确保了消息的可靠传递和处理,避免了重复数据的出现。
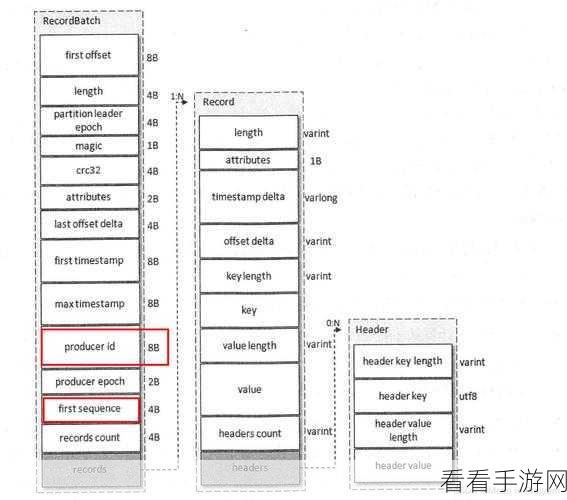
Kafka 幂等性下的数据归档有哪些要点呢?需要合理设置数据的保留策略,根据业务需求和数据的重要程度,确定数据在 Kafka 中的留存时间,要优化数据的存储结构,以提高归档的效率和便捷性,监控数据的流入和流出,及时发现异常情况并进行处理。
在进行数据归档时,还需要注意数据的安全性和完整性,采取加密等措施保障数据在归档过程中的安全,同时通过校验等手段确保数据的完整。
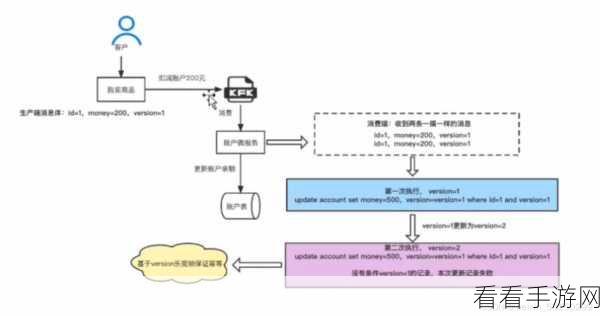
充分利用 Kafka 提供的工具和 API 也是必不可少的,这些工具和 API 能够帮助我们更高效地实现数据归档的操作。
掌握 Kafka 幂等性的数据归档并非易事,需要综合考虑多方面的因素,并在实践中不断摸索和优化,才能达到理想的效果。
文章参考来源:相关技术文档及行业经验总结。
