深度解析,Kafka 幂等性实现数据同步的关键技巧
在当今数字化的时代,数据的同步与处理成为了众多应用和系统面临的重要挑战,Kafka 作为一款强大的分布式消息队列系统,其幂等性在确保数据准确同步方面发挥着关键作用,我们将深入探讨 Kafka 幂等性如何巧妙地进行数据同步。
中心句:在数字化时代,数据同步与处理是重要挑战,Kafka 幂等性在其中作用关键。
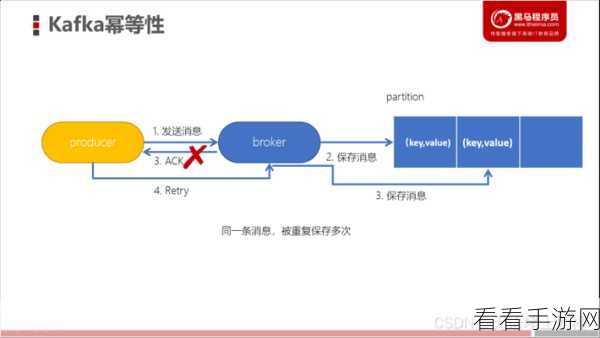
Kafka 幂等性的原理其实并不复杂,但要实现高效的数据同步,需要对其有深入的理解,幂等性就是指多次执行同一种操作所产生的结果与执行一次操作的结果相同,这一特性在数据同步中极为重要,能够有效避免重复数据的写入,保证数据的一致性和准确性。
中心句:Kafka 幂等性原理不复杂,但其在实现高效数据同步中需深入理解,能避免重复数据写入。
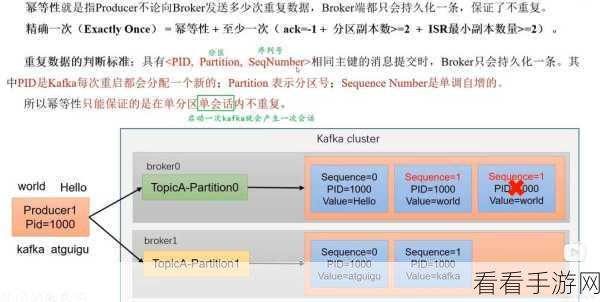
要实现 Kafka 幂等性的数据同步,首先需要对生产者和消费者的配置进行精心调整,生产者方面,需要设置合适的参数,例如启用幂等性选项,并确保消息的唯一标识能够准确生成,对于消费者,要合理设置消费策略,以正确处理可能出现的重复消息。
中心句:实现 Kafka 幂等性的数据同步,需精心调整生产者和消费者的配置。
还需要关注数据的分区和副本机制,合理的分区策略可以提高数据的并行处理能力,而副本机制则为数据的可靠性提供了保障,在数据同步过程中,要充分利用这些机制,优化数据的传输和存储。
中心句:关注数据的分区和副本机制,能在数据同步中优化传输和存储。
监控和错误处理也是不可忽视的环节,通过实时监控数据同步的状态和指标,可以及时发现潜在的问题,并采取相应的措施进行解决,对于可能出现的错误,要有完善的错误处理机制,以保证数据同步的稳定性和连续性。
中心句:监控和错误处理在数据同步中不可忽视,能保证稳定性和连续性。
掌握 Kafka 幂等性实现数据同步并非一蹴而就,需要综合考虑多个因素,并不断实践和优化,只有这样,才能在复杂的业务场景中充分发挥 Kafka 的优势,实现高效、准确的数据同步。
文章参考来源:相关技术文档及行业研究报告。
希望以上内容对您有所帮助!
