探秘 Kafka C 数据同步的高效之法
在当今数字化时代,数据同步成为了众多应用场景中的关键环节,特别是在使用 Kafka 和 C# 进行开发时,如何实现高效的数据同步更是备受关注。
Kafka 作为一款强大的分布式消息队列系统,在处理大量数据时表现出色,而 C# 作为一种广泛应用的编程语言,为开发者提供了丰富的工具和库。
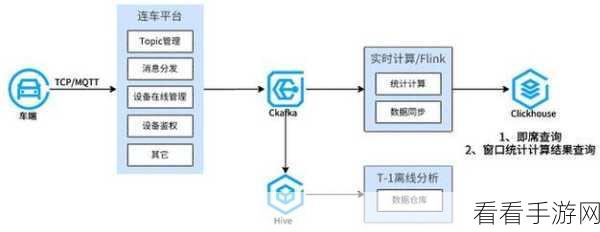
要实现 Kafka C# 的数据同步,我们需要先了解 Kafka 的基本原理和工作机制,Kafka 基于发布/订阅模式,通过主题(Topic)来组织数据,数据被分成多个分区(Partition),以实现并行处理和高吞吐量。
在 C# 中,我们可以利用一些优秀的开源库来与 Kafka 进行交互,Confluent.Kafka 就是一个常用的库。
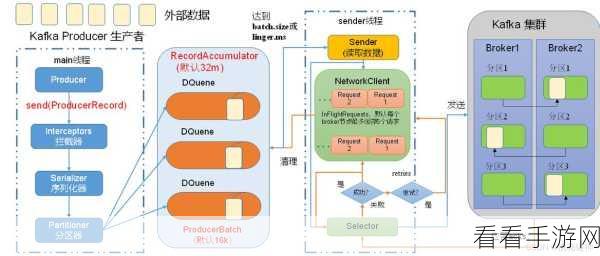
我们需要配置相关的参数,如服务器地址、主题名称、消费者组等,正确的配置是确保数据同步成功的重要基础。
然后是处理数据的逻辑,在消费数据时,我们要根据具体的业务需求进行处理,可能包括数据转换、存储、计算等操作。
还需要考虑错误处理和异常情况,当数据同步过程中出现网络故障、服务器异常等问题时,要有相应的恢复机制和错误处理策略,以保证数据的完整性和一致性。
实现 Kafka C# 的数据同步需要综合考虑多个方面,从原理的理解到实际的代码实现,每一个环节都至关重要,只有精心设计和优化,才能确保数据同步的高效和稳定。
参考来源:相关技术文档及开发经验总结。
