破解 Kafka 消费模型的数据同步之谜
Kafka 消费模型中的数据同步,一直以来都是技术领域备受关注的重要课题。
在当今数字化时代,数据的高效处理和准确同步至关重要,Kafka 作为一种强大的消息队列系统,其消费模型的数据同步机制直接影响着整个系统的性能和稳定性。
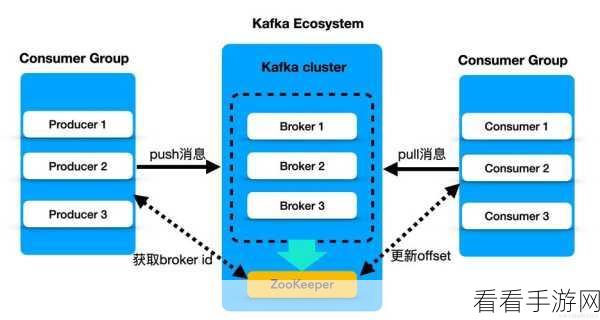
要深入理解 Kafka 消费模型的数据同步,首先需要明确其基本原理,Kafka 采用了分布式架构,通过分区和副本机制来实现数据的存储和同步,在数据同步过程中,消费者从 Broker 中读取数据,并根据一定的策略进行处理和消费。
Kafka 消费模型的数据同步还涉及到众多关键因素,网络延迟、消费者的处理能力、数据量的大小等,都会对同步效果产生影响,为了优化数据同步,我们可以从多个方面入手。
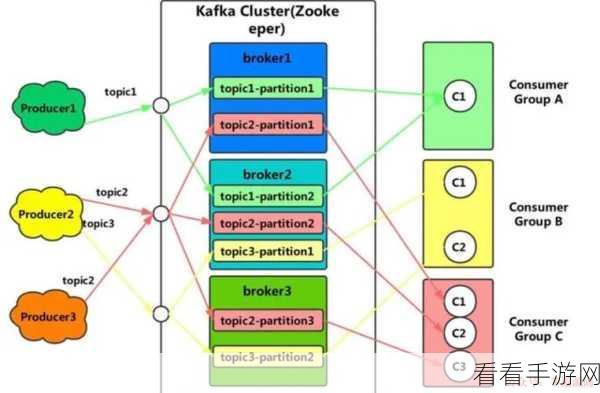
合理配置 Kafka 的参数是关键,调整分区数量、副本因子、消息留存时间等参数,能够根据实际业务需求来优化数据同步的性能。
选择合适的消费策略也非常重要,不同的消费策略在处理数据同步时有着不同的表现,例如自动提交偏移量和手动提交偏移量的策略,需要根据具体场景进行权衡和选择。
监控和优化系统性能也是必不可少的,通过实时监控 Kafka 集群的各项指标,如吞吐量、延迟、资源利用率等,及时发现并解决潜在的问题,从而保障数据同步的稳定性和高效性。
掌握 Kafka 消费模型的数据同步,需要对其原理有深入的理解,同时结合实际业务需求,从参数配置、消费策略选择和系统性能优化等多个角度进行综合考虑和处理。
参考来源:相关技术文档和行业研究报告。
