探索 Kafka 消费模型的数据备份秘籍
Kafka 消费模型的数据备份至关重要,它是保障数据安全和业务连续性的关键环节。
Kafka 作为一种强大的分布式消息队列系统,在处理海量数据时表现出色,要确保数据的可靠备份并非易事。
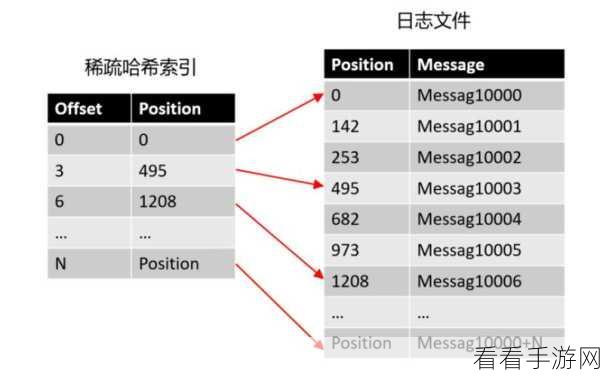
对于 Kafka 消费模型的数据备份,我们需要明确几个核心要点,要深入了解 Kafka 的存储机制,Kafka 将数据存储在分区中,每个分区又由多个副本组成,备份数据时,需要考虑这些分区和副本的分布情况,以确保备份的完整性和准确性。
选择合适的备份工具和技术也十分关键,常见的备份工具如 Kafka Connect 可以帮助我们实现高效的数据备份,利用云存储服务来存储备份数据也是一种不错的选择,能够提供可靠的存储和便捷的恢复机制。
制定合理的备份策略也是必不可少的,根据数据的重要性和更新频率,确定备份的时间间隔和保留周期,要建立备份的验证机制,定期检查备份数据的可用性和完整性。
在实际操作中,还需要注意备份过程中的性能影响,尽量避免备份操作对正常的业务处理造成过大的压力,通过合理的资源分配和优化备份流程来降低影响。
成功实现 Kafka 消费模型的数据备份需要综合考虑多个因素,从深入理解其存储机制到选择合适的工具和策略,再到优化备份过程中的性能,每一个环节都不能忽视,只有这样,才能为数据安全提供坚实的保障。
文章参考来源:相关技术文档和行业实践经验。
