Spark SortBy 效率提升秘籍大揭秘
Spark 中的 SortBy 操作在数据处理中扮演着重要角色,然而如何提升其效率却让不少开发者感到困惑,本文将深入探讨提升 Spark SortBy 效率的方法和技巧,帮助您优化数据处理流程。
要提升 Spark SortBy 的效率,关键在于理解其工作原理和数据特点,SortBy 操作需要对数据进行排序,而数据的分布、规模以及排序的键等因素都会影响效率。
优化数据分区是一个重要的策略,通过合理设置分区数量和分区方式,可以减少数据在节点之间的传输,从而提高排序效率,选择合适的排序算法也能带来显著的性能提升,不同的场景下,某些特定的排序算法可能更适合处理特定类型的数据。
缓存常用数据也是提升效率的有效手段,将频繁使用的数据进行缓存,可以避免重复计算和数据读取,节省时间和资源。
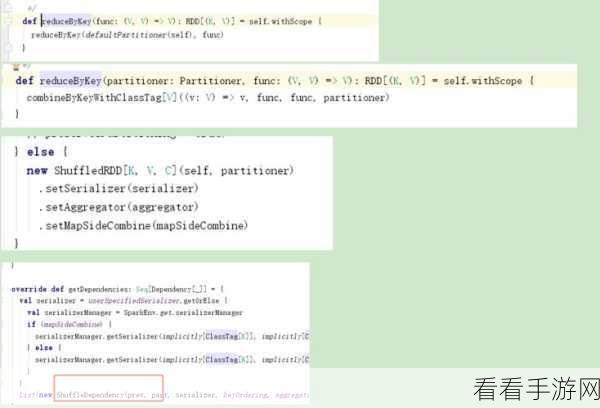
对数据进行预处理也能为 SortBy 操作减轻负担,提前过滤掉不必要的数据,或者对数据进行初步的分类和整理,都有助于提高后续排序的效率。
提升 Spark SortBy 效率需要综合考虑多个因素,并根据实际情况选择合适的优化策略,只有不断探索和实践,才能在数据处理中取得更好的性能表现。
参考来源:相关技术文档及实践经验总结。
