深度解析,Spark SortBy 背后的神秘原理
Spark SortBy 是大数据处理中一个非常重要的操作,理解其原理对于优化数据处理流程至关重要。
Spark SortBy 主要基于分布式计算框架实现数据的排序,在这个过程中,数据会被分割成多个分区,并在各个节点上进行局部排序,通过特定的算法和机制,将这些局部排序的结果进行合并,最终得到整体有序的数据。
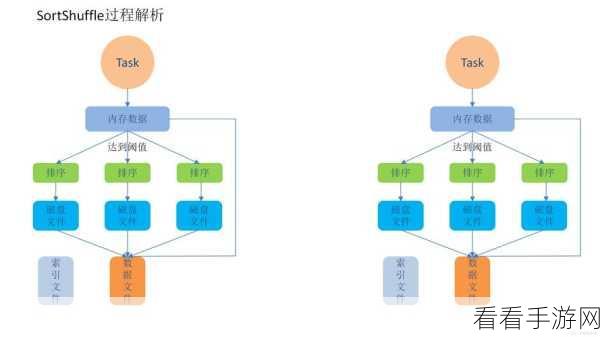
Spark SortBy 的实现涉及到多个关键技术,它利用了高效的排序算法,以确保在大规模数据下仍能保持较好的性能,对于数据的分区和合并,也有着精细的策略,以减少数据传输和计算的开销。
要深入理解 Spark SortBy 的原理,还需要考虑到其与内存管理、数据类型以及任务调度的紧密结合,良好的内存管理能够避免数据溢出,提高排序的效率;不同的数据类型可能需要不同的处理方式,以保证排序的准确性;而合理的任务调度则能够充分利用集群的资源,加快排序的速度。
掌握 Spark SortBy 的原理,不仅有助于提升大数据处理的效率和质量,还能为开发更复杂的应用提供坚实的基础。
参考来源:相关技术文档及专业书籍。
仅供参考,您可以根据实际需求进行调整。
