深入探究,Spark 函数的强大功能实现之道
Spark 函数在当今的技术领域中发挥着至关重要的作用,掌握其功能实现的方法对于开发者和数据处理人员来说具有极大的价值。
Spark 函数之所以备受关注,是因为它能够高效处理大规模数据,并提供灵活多样的操作方式,要理解 Spark 函数如何实现功能,首先需要对 Spark 框架有一个基本的认识。
Spark 是一个快速、通用的大数据处理框架,它具有分布式计算的能力,可以在大规模集群上并行处理数据,而 Spark 函数正是在这个框架中发挥作用的关键组件。
在 Spark 中,常见的函数类型包括转换函数和行动函数,转换函数用于对数据进行各种转换操作,比如映射、过滤、聚合等,行动函数则用于触发实际的计算并返回结果。
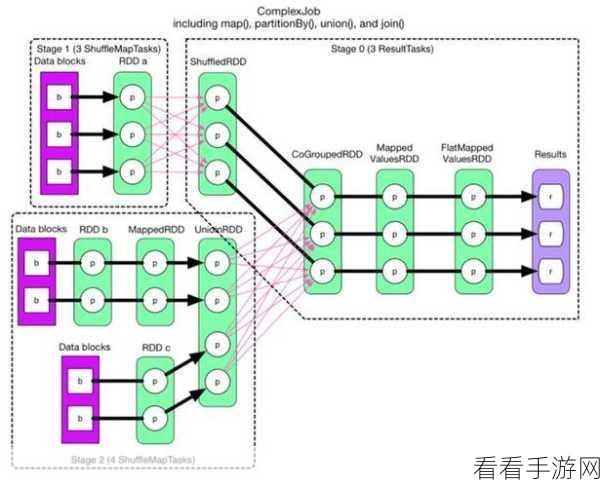
以映射函数为例,它可以将输入数据集中的每个元素按照指定的规则进行转换,生成新的数据集,将一个包含整数的数据集通过映射函数转换为对应的平方值。
过滤函数则用于根据指定的条件筛选出符合要求的数据,从一个包含学生成绩的数据集里筛选出成绩大于 80 分的学生记录。
聚合函数能够对数据进行汇总计算,如求和、求平均值、求最大值和最小值等。
为了更好地运用 Spark 函数,还需要了解其在不同场景下的优化策略,合理设置分区数量、选择合适的数据结构以及利用缓存机制等。
深入理解和熟练掌握 Spark 函数的功能实现,能够帮助我们在大数据处理中更加高效地完成各种任务,为数据驱动的决策提供有力支持。
文章参考来源:相关技术文档及专业书籍。
