深度解析,Kafka 幂等性的强大功能与实际应用
Kafka 幂等性,这一概念在大数据处理和消息传递领域中扮演着至关重要的角色。
Kafka 幂等性能够确保消息在处理过程中的准确性和一致性,在分布式系统中,由于网络延迟、故障等原因,消息可能会被重复发送,而幂等性机制可以保证即使消息被多次处理,最终的结果也能保持一致,避免了数据的错误和不一致性。
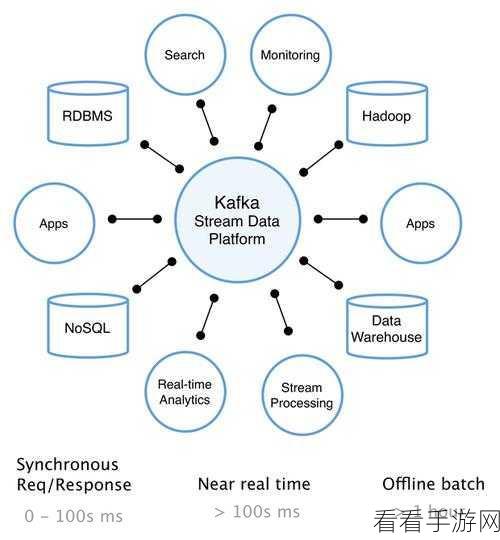
Kafka 幂等性的实现依赖于一些关键技术和策略,它通过为每条消息分配一个唯一的标识符,在处理消息时进行标识符的校验,从而判断该消息是否已经被处理过,如果是已经处理过的消息,就不再进行重复处理,从而有效地避免了重复操作带来的问题。
要充分发挥 Kafka 幂等性的优势,还需要在实际应用中进行合理的配置和优化,根据业务需求调整相关的参数,以确保幂等性机制能够与系统的其他部分协同工作,达到最佳的性能和效果。
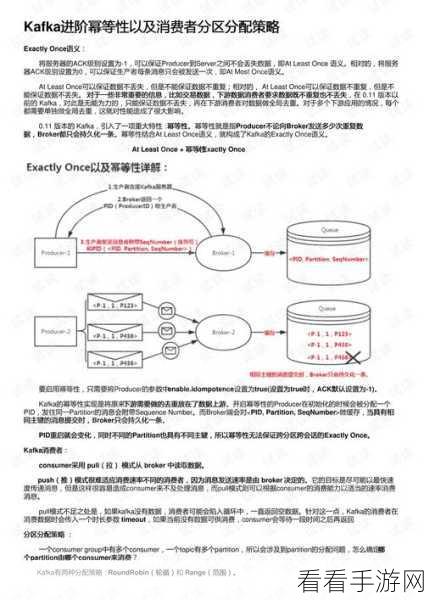
在实际的项目开发中,Kafka 幂等性已经得到了广泛的应用,比如在电商系统中,处理订单相关的消息时,幂等性可以保证订单状态的准确更新,避免出现重复下单或订单状态混乱的情况。
Kafka 幂等性是保障数据可靠性和一致性的重要手段,对于构建稳定、高效的分布式系统具有不可忽视的作用,深入理解和合理应用 Kafka 幂等性,将为您的系统开发和业务运营带来显著的价值。
文章参考来源:相关技术文档和行业研究报告。
