掌握 C UnicodeEncoding 编码方式的关键选择指南
在进行 C# 编程时,选择合适的 UnicodeEncoding 编码方式至关重要,这不仅影响着程序的正确性和稳定性,还关系到数据的传输与存储效果。
C# 中的 UnicodeEncoding 编码方式具有多种选项,每种都有其独特的特点和适用场景,要做出明智的选择,就需要深入了解它们的差异和优势。
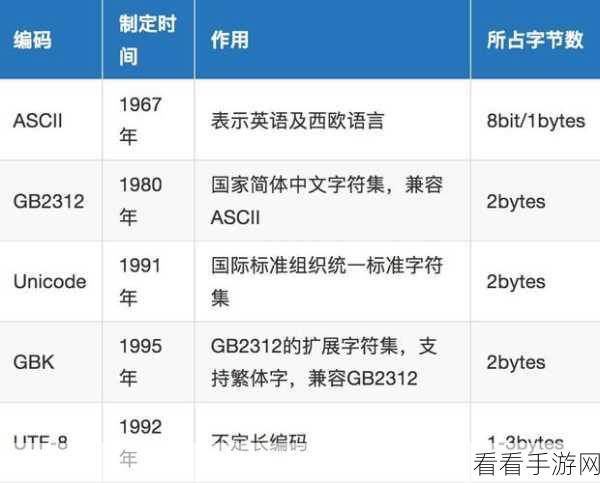
我们先来看看 UTF-8 编码方式,UTF-8 是一种变长编码,它能够有效地节省存储空间,特别是对于包含大量 ASCII 字符的文本,UTF-8 在网络传输中也具有广泛的支持,使其成为跨平台数据交换的常用选择。
接下来是 UTF-16 编码,UTF-16 采用固定的 16 位编码单元,对于处理包含大量非 ASCII 字符的文本时效率较高,它在存储空间上相对较大,在某些特定场景下可能不太适用。
还有 UTF-32 编码,这种编码方式使用固定的 32 位编码单元,虽然处理起来简单直接,但存储空间消耗巨大,一般只在特定的高性能计算或对编码精度要求极高的情况下使用。
在实际应用中,我们需要根据具体的需求来选择编码方式,如果对存储空间要求较高,同时文本中 ASCII 字符占比较大,UTF-8 可能是最佳选择,如果处理的文本主要是非 ASCII 字符,且对处理效率有较高要求,UTF-16 则更为合适,而对于一些特殊的高精度需求场景,才考虑使用 UTF-32 编码。
选择 C# UnicodeEncoding 编码方式并非随意之举,需要综合考虑各种因素,以达到最佳的编程效果。
文章参考来源:相关 C# 编程技术文档及专业书籍。
