掌握 Kafka 消费模型选型秘籍,开启高效数据处理之旅
Kafka 作为一款强大的分布式消息队列系统,其消费模型的选型至关重要,不同的消费模型在性能、可靠性、扩展性等方面存在差异,因此正确选型能够极大地提升系统的整体效率和稳定性。
在实际应用中,Kafka 提供了多种消费模型供开发者选择,常见的有自动提交偏移量的消费模型、手动提交偏移量的消费模型以及基于组的消费模型等。
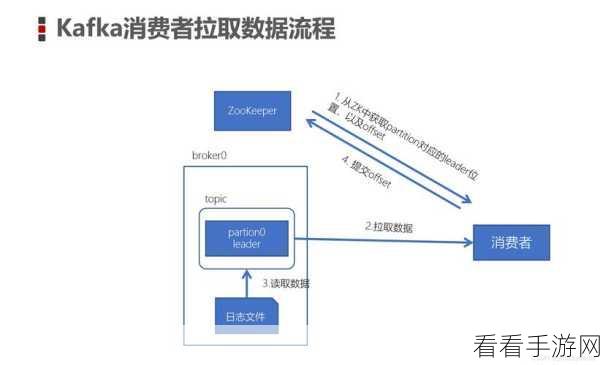
对于自动提交偏移量的消费模型,其优点在于操作简单,开发者无需过多关注偏移量的处理,但缺点是可能会出现重复消费或数据丢失的情况,这种模型适用于对数据准确性要求不高,但对系统性能和响应速度有较高要求的场景。
手动提交偏移量的消费模型则给予了开发者更多的控制权,通过手动管理偏移量,可以更精确地控制消费进度,避免数据丢失和重复消费,这也增加了开发的复杂性,需要开发者具备一定的技术能力和经验,手动提交偏移量的消费模型适用于对数据准确性要求极高的业务场景。
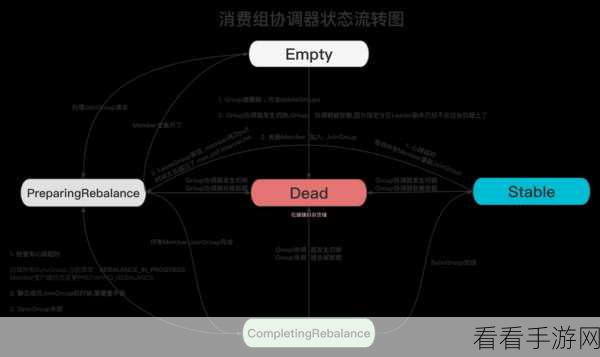
基于组的消费模型则实现了多个消费者之间的负载均衡和协同工作,通过将消费者分组,可以实现数据的分区消费,提高系统的并发处理能力,但在使用过程中,需要注意组内消费者的协调和管理,以避免出现消费异常的情况。
在进行 Kafka 消费模型选型时,需要综合考虑业务需求、系统性能、数据准确性等多方面因素,如果业务对实时性要求较高,可以选择自动提交偏移量的消费模型;如果对数据准确性要求苛刻,则手动提交偏移量的消费模型更为合适;而对于需要大规模并发处理的场景,基于组的消费模型则能发挥更大的优势。
Kafka 消费模型的选型是一个复杂但重要的任务,需要开发者深入理解各种模型的特点和适用场景,结合实际业务需求进行权衡和选择,才能构建出高效、稳定的消息处理系统。
参考来源:相关技术文档及行业实践经验。
