深度解析,Kafka 消费模型保障数据一致性的秘诀
Kafka 作为一种强大的分布式消息队列,其消费模型在确保数据一致性方面发挥着至关重要的作用。
Kafka 消费模型之所以能够保障数据一致性,关键在于其独特的设计和机制,Kafka 采用了分区的概念,将数据分散存储在不同的分区中,每个分区都有自己独立的偏移量,这使得消费者可以在不同的分区上并行处理数据,提高了消费的效率和灵活性。
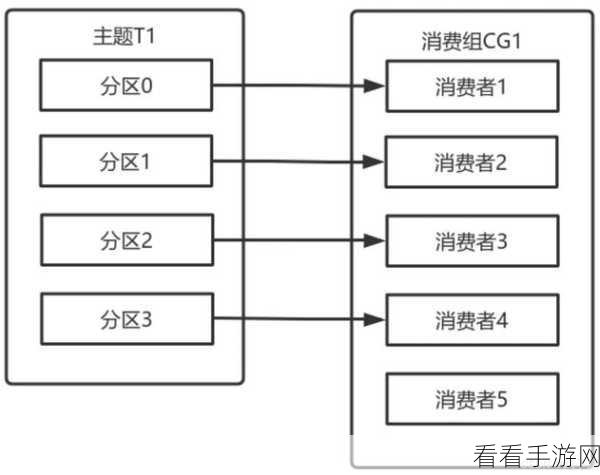
Kafka 提供了多种消费模式,如自动提交偏移量和手动提交偏移量,自动提交偏移量模式相对简单,但可能会在某些情况下导致数据一致性问题,而手动提交偏移量模式则给予了消费者更多的控制,允许他们在确认处理完数据后再进行偏移量的提交,从而确保数据不会被重复处理或丢失。
Kafka 还通过副本机制来保证数据的可靠性,每个分区都有多个副本,当主副本出现故障时,其他副本可以迅速接管,确保数据的可用性和一致性。
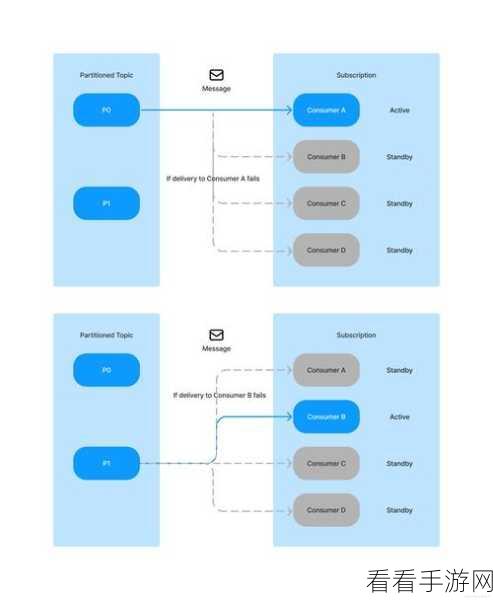
在实际应用中,为了更好地利用 Kafka 消费模型确保数据一致性,我们需要注意一些关键要点,合理设置消费组的消费者数量,避免过多或过少导致的资源浪费或处理延迟,要根据业务需求选择合适的消费模式,并对偏移量的提交进行谨慎管理。
深入理解 Kafka 消费模型的原理和机制,结合实际业务场景进行合理的配置和优化,是确保数据一致性的关键所在。
参考来源:相关技术文档和权威论坛的讨论。
围绕“Kafka 消费模型如何确保数据一致性”进行了展开,通过分析其关键设计和机制,以及实际应用中的注意要点,为读者提供了全面而深入的解读。
