Python Spider 爬虫处理 HTTP 头部信息的秘籍大公开
在当今数字化时代,Python 语言因其强大的功能和简洁的语法,在爬虫领域备受青睐,而处理 HTTP 头部信息对于 Python Spider 是一项至关重要的任务。
HTTP 头部信息包含了丰富的与请求和响应相关的元数据,如用户代理、内容类型、缓存控制等,理解并正确处理这些信息,能够帮助爬虫更有效地获取所需数据,同时避免不必要的错误和限制。
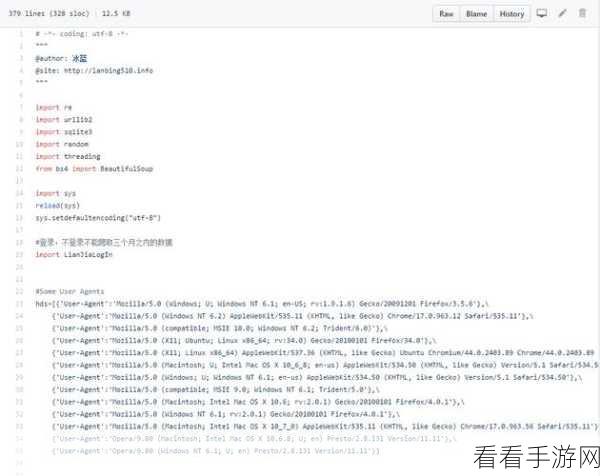
要成功处理 HTTP 头部信息,首先需要了解常见的头部字段及其含义。“User-Agent”字段用于标识发出请求的客户端类型,通过设置合适的用户代理,可以模拟不同的浏览器或客户端,降低被反爬虫机制识别的风险。
掌握发送和接收 HTTP 头部信息的方法也很关键,在 Python 中,可以使用诸如“requests”库等工具来实现,通过设置请求头参数,能够向服务器传递特定的信息,从而满足服务器的要求,获取到预期的响应。
对于服务器返回的响应头部信息,需要进行仔细的解析和处理,这有助于判断响应的状态、内容类型以及是否存在缓存等重要信息,为后续的数据处理和存储提供依据。
在实际应用中,还需要注意遵守相关的法律法规和网站的使用规则,避免非法或不道德的爬虫行为。
熟练掌握 Python Spider 爬虫处理 HTTP 头部信息的技巧,将为您的爬虫开发工作带来极大的便利和效率提升。
文章参考来源:相关 Python 爬虫技术书籍及网络技术论坛。
