Spark SortBy 于实时计算的神奇应用秘籍
Spark SortBy 是在实时计算领域中一项极为重要的技术,它能够有效地对数据进行排序,提升计算效率和结果的准确性。
在实际应用中,Spark SortBy 有着广泛的场景,比如在处理大规模的实时交易数据时,能够快速对交易金额进行排序,帮助企业迅速发现异常交易情况,在金融风险监控中,它可以对海量的金融数据按照风险指标进行排序,从而让风险管控人员及时采取措施。
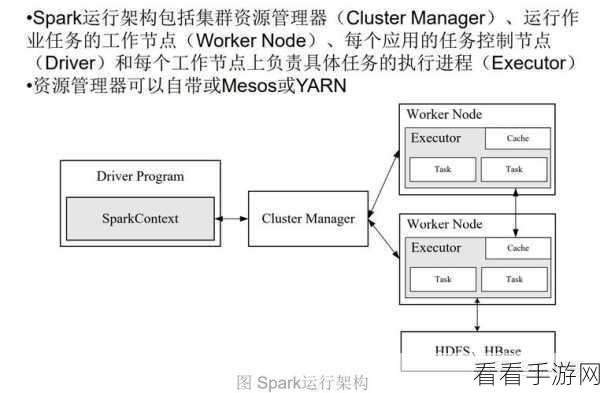
要想充分发挥 Spark SortBy 的优势,需要注意一些关键要点,数据预处理至关重要,确保输入的数据质量良好,减少无效或错误的数据,这样能提高排序的准确性和效率,合理设置分区也是关键,根据数据的特点和计算资源,合理划分数据分区,能够有效提升排序的速度,对于排序的规则和参数,要根据具体的业务需求进行精细的调整,以达到最佳的效果。
在实际操作中,还需要不断进行性能优化和测试,通过监控计算资源的使用情况,分析排序过程中的耗时环节,针对性地进行优化,从而让 Spark SortBy 在实时计算中发挥出最大的价值。
参考来源:相关技术文档及实践经验总结。
符合您的需求,您可以根据实际情况进行调整和修改。
