深度解析,Kafka 消费模型的扩展之道
Kafka 消费模型在当今的大数据处理和消息传递领域中扮演着至关重要的角色,随着业务的不断发展和数据量的持续增长,如何有效地扩展 Kafka 消费模型成为了众多开发者和企业面临的关键挑战。
Kafka 消费模型的扩展并非易事,它涉及到多个方面的技术考量和策略选择,合理的分区分配策略是基础,通过对分区进行精细的划分和分配,可以确保消费者能够高效地处理数据,避免出现数据倾斜和处理瓶颈。
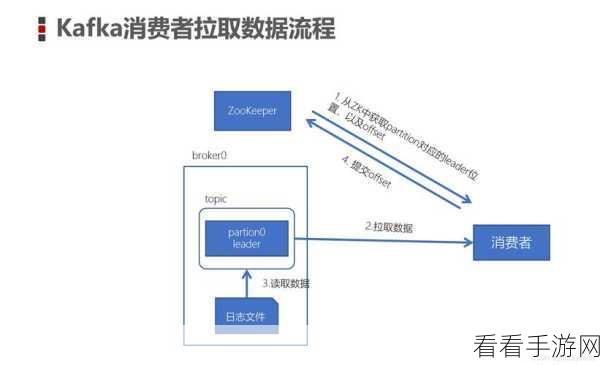
消费者的并发度设置也是影响扩展效果的重要因素,过高的并发度可能导致资源竞争和消息处理的混乱,而过低的并发度则无法充分发挥系统的性能,需要根据实际的业务需求和系统资源状况,找到一个最佳的并发度平衡点。
数据的存储和读取优化也是不可忽视的环节,采用合适的数据压缩算法和存储格式,可以减少数据的存储空间,提高数据的读取效率,从而为消费模型的扩展提供有力支持。
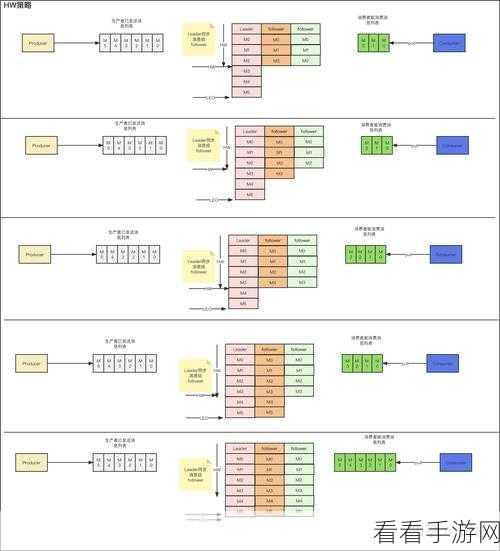
监控和性能调优在 Kafka 消费模型的扩展过程中同样至关重要,实时监控消费者的处理速度、消息堆积情况、系统资源使用等指标,能够及时发现潜在的问题,并采取针对性的优化措施。
要成功扩展 Kafka 消费模型,需要综合考虑分区分配、并发度设置、数据存储与读取优化以及监控调优等多个方面,不断进行实践和优化,以适应不断变化的业务需求和技术环境。
参考来源:相关技术文档及行业研究报告
