探秘 Spark SortBy 与 Hive 的完美集成之道
在当今的大数据处理领域,Spark 和 Hive 都是极其重要的工具,而如何实现 Spark SortBy 与 Hive 的集成,成为众多开发者关注的焦点。
Spark SortBy 是 Spark 中用于对数据进行排序的操作,具有高效和灵活的特点,Hive 则是基于 Hadoop 的数据仓库工具,能够方便地进行大规模数据的存储和查询。
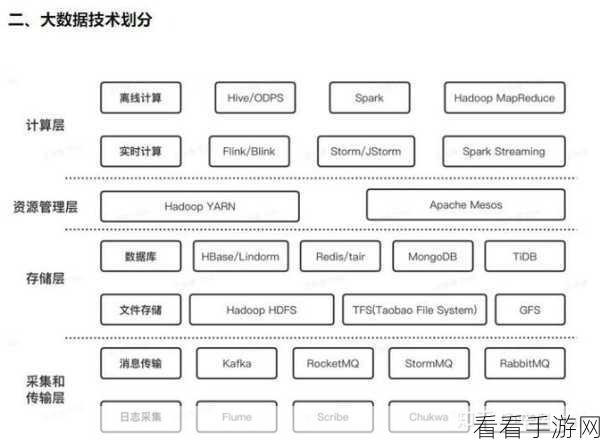
要实现 Spark SortBy 与 Hive 的集成,首先需要了解两者的数据结构和处理方式,Spark 中的数据通常以弹性分布式数据集(RDD)或 DataFrame 的形式存在,而 Hive 中的数据则存储在表中,在进行集成时,需要将 Hive 表中的数据转换为 Spark 可处理的格式。
配置环境也是至关重要的一步,需要确保 Spark 和 Hive 的版本兼容,并正确设置相关的配置参数,如 Hive 的 metastore 地址等。
编写合适的代码来实现集成也是关键,可以使用 Spark 的 API 来读取 Hive 表中的数据,并应用 SortBy 操作进行排序。
在实际的应用中,还需要考虑性能优化的问题,合理调整分区数量、使用缓存等技巧,以提高集成的效率。
成功实现 Spark SortBy 与 Hive 的集成并非易事,需要对两者有深入的理解和熟练的技术运用,但一旦完成集成,将为大数据处理带来更强大的能力和更高的效率。
文章参考来源:相关技术文档和实践经验总结。
