探秘 Spark 函数的分布式计算秘籍
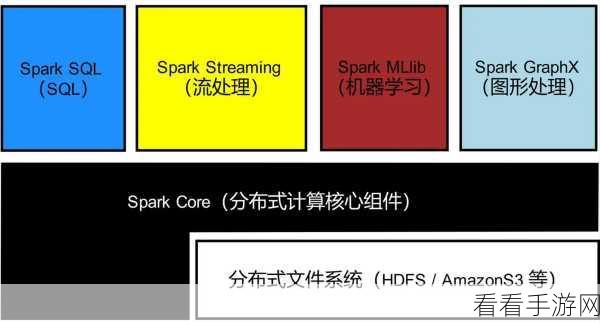
Spark 函数的分布式计算,一直以来都是技术领域的热门话题,它在处理大规模数据时展现出了强大的能力,为数据处理和分析带来了高效与便捷。
Spark 函数之所以能够实现分布式计算,关键在于其独特的架构和设计理念,它将计算任务分解为多个小的子任务,并在集群中的多个节点上并行执行,这种并行处理的方式大大提高了计算的速度和效率。
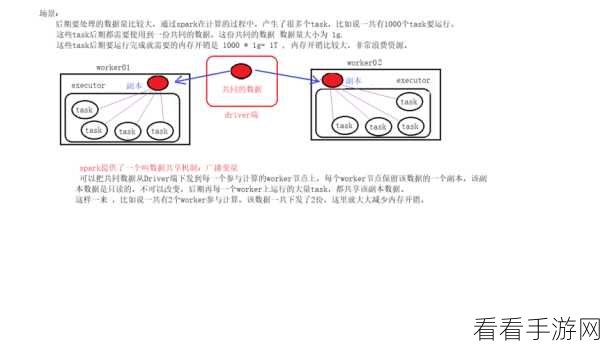
在实际应用中,要想充分发挥 Spark 函数分布式计算的优势,需要合理配置资源,包括内存、CPU 核心数以及网络带宽等方面的优化,对于数据的分区和分布也需要精心设计,以确保各个节点的负载均衡,避免出现某些节点过度繁忙而其他节点闲置的情况。
编程技巧也是至关重要的,熟练掌握 Spark 提供的各种 API 和函数,能够编写出高效、简洁的代码,使用合适的转换操作和行动操作,能够有效地减少数据的传输和计算量。
在错误处理方面,要提前考虑可能出现的异常情况,并制定相应的处理策略,这样可以在计算过程中遇到问题时,快速定位并解决,保证计算任务的顺利进行。
要深入理解和运用 Spark 函数的分布式计算,需要综合考虑多个方面的因素,只有在架构、资源配置、编程技巧和错误处理等方面都做到位,才能充分发挥其强大的功能,为数据处理和分析提供有力支持。
文章参考来源:相关技术文档及专业论坛讨论。
