探秘 Hive Grouping 处理大数据集的分页查询技巧
在当今数字化时代,大数据的处理成为了众多企业和开发者面临的重要挑战,Hive Grouping 在处理大数据集时的分页查询更是备受关注。
Hive Grouping 是一种强大的数据处理方式,但在面对海量数据时,如何进行高效的分页查询并非易事。
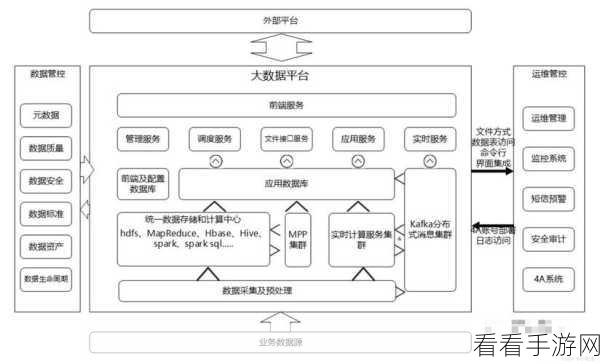
想要实现 Hive Grouping 处理大数据集的有效分页查询,需要从多个方面入手,首先要明确数据的分布特点和查询需求,了解数据的特征能够帮助我们选择合适的查询策略,从而提高查询效率。
优化查询语句也是关键所在,合理运用索引、分区等技术,可以大幅减少数据的扫描量,加快查询速度。
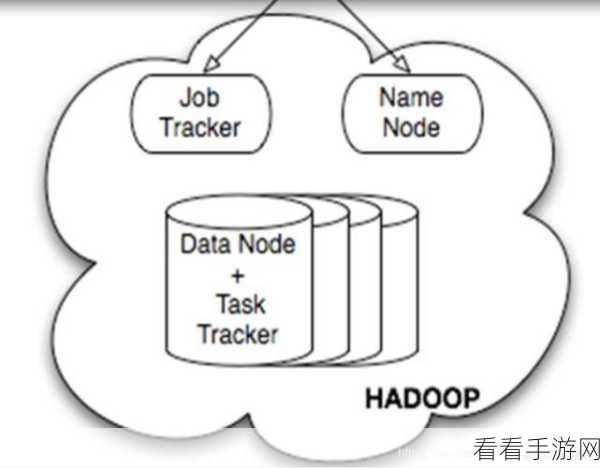
调整 Hive 的配置参数也能对分页查询产生积极影响,适当增加并行度、调整内存分配等,能够提升系统的整体性能。
还可以结合外部工具和技术来增强分页查询的效果,比如使用缓存机制,将经常查询的数据提前缓存,减少重复计算。
在实际应用中,我们需要根据具体的场景和需求,灵活选择和组合上述方法,以达到最佳的分页查询效果。
参考来源:相关技术文档及实践经验总结
仅供参考,您可以根据实际需求进行调整和修改。
