Kafka C 数据序列化实战攻略
在当今的软件开发领域,Kafka 和 C# 的结合应用愈发广泛,而其中,数据序列化是一个关键环节,就让我们一同深入探讨 Kafka C# 如何进行数据序列化。
数据序列化对于 Kafka C# 应用的重要性不言而喻,它决定了数据在传输和存储过程中的效率与准确性,高效且准确的数据序列化,能够极大地提升整个系统的性能和稳定性。
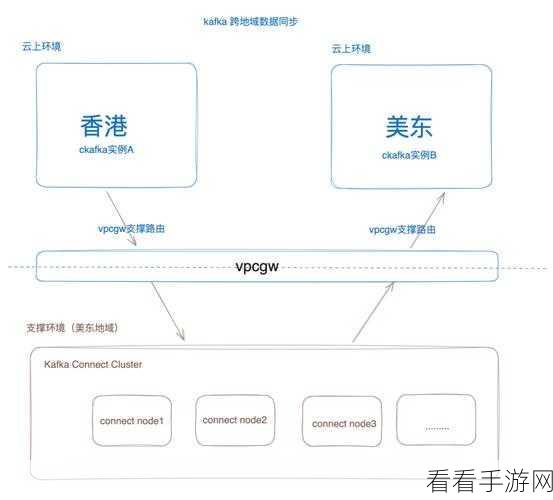
要实现 Kafka C# 的数据序列化,首先需要了解相关的序列化框架和工具,常见的有 ProtoBuf、JSON 等,这些框架和工具各有特点,需要根据具体的业务需求进行选择。
在选择好序列化框架后,就需要进行相应的配置和编码工作,以 ProtoBuf 为例,需要定义数据的结构,并使用相应的生成工具生成 C# 代码,在实际的编码中,按照框架的规则进行数据的序列化和反序列化操作。
还需要注意数据类型的匹配和处理,不同的序列化框架对于数据类型的支持和处理方式可能有所不同,如果数据类型处理不当,可能会导致序列化失败或者数据丢失。
在进行数据序列化的过程中,性能优化也是不可忽视的一个方面,可以通过合理设置缓冲区大小、优化序列化算法等方式来提高序列化的速度和效率。
Kafka C# 的数据序列化并非一蹴而就,需要综合考虑多个因素,并不断进行实践和优化,只有这样,才能确保在实际应用中达到最佳的效果。
文章参考来源:相关技术文档及个人实践经验。
