探索 Hive Hash 在 Join 操作中的独特魅力与显著优势
Hive 作为大数据处理领域的重要工具,其 Hash Join 操作具有不可忽视的优势,在当今数据处理需求日益复杂的背景下,深入了解 Hive Hash 在 Join 操作中的出色表现,对于提升数据处理效率和质量具有关键意义。
Hive Hash Join 操作的优势首先体现在其高效的内存利用上,传统的 Join 方法可能会因为数据量过大而导致内存溢出,影响处理效率,Hive Hash 通过巧妙的算法,能够在有限的内存空间内对数据进行快速匹配和关联,大大降低了内存消耗,从而提高了整个处理过程的速度。
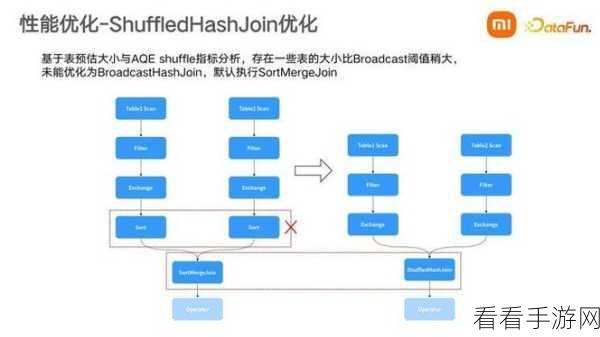
Hive Hash Join 在处理大规模数据时表现出色,面对海量的数据,它能够迅速构建哈希表,并通过哈希函数快速定位和匹配相关数据,减少了不必要的扫描和比较操作,使得处理时间大幅缩短。
Hive Hash Join 具有良好的可扩展性,随着数据规模的不断增长,它可以轻松应对,通过分布式计算框架实现并行处理,进一步提升处理能力,满足业务不断发展的需求。
Hive Hash Join 还提供了更灵活的配置选项,用户可以根据具体的业务场景和数据特点,调整哈希函数、分区策略等参数,以实现最优的处理效果。
Hive Hash 在 Join 操作中的优势是多方面的,为大数据处理带来了更高效、更灵活、更可靠的解决方案。
文章参考来源:相关 Hive 技术文档及大数据处理领域的研究报告。
