Python Scrapy 爬虫,实用价值大揭秘
Python Scrapy 爬虫,作为一项技术工具,在数据采集领域备受关注,它到底好不好用呢?
Scrapy 爬虫具有众多显著的优点,它是一个功能强大且高效的框架,能够快速且准确地抓取大量数据,其灵活性让开发者可以根据具体需求定制爬虫规则,轻松应对各种复杂的网站结构,Scrapy 拥有活跃的社区支持,遇到问题时,能够在社区中找到丰富的解决方案和经验分享。
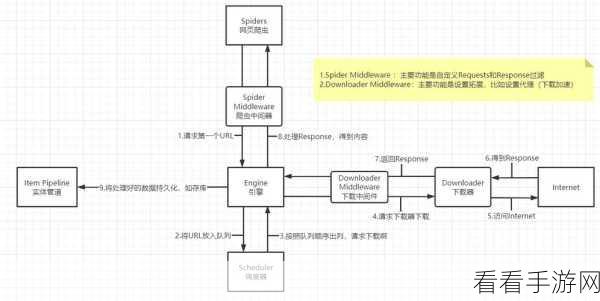
Scrapy 爬虫也并非十全十美,对于初学者来说,它的学习曲线相对较陡峭,需要掌握一定的编程基础和网络知识,在某些情况下,由于网站的反爬虫机制,可能会导致抓取数据遇到阻碍。
要想充分发挥 Scrapy 爬虫的优势,需要掌握一些关键技巧,合理设置请求头和代理,模拟真实的用户访问行为,降低被反爬虫机制识别的风险,对抓取到的数据进行有效的清洗和处理,也是确保数据质量的重要环节。
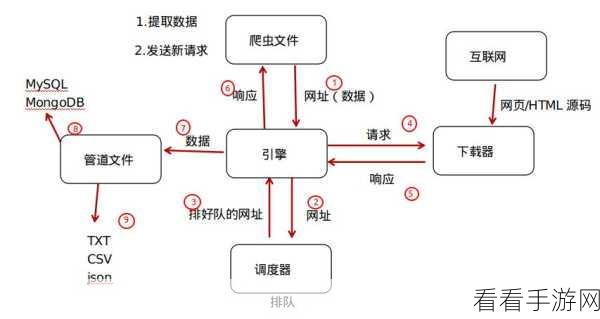
Python Scrapy 爬虫在数据采集方面具有强大的功能,但也存在一定的挑战,只有充分了解其特点,并掌握相应的技巧,才能更好地利用它为我们的工作和研究服务。
参考来源:相关技术论坛及专业书籍。
