Hive Beeline 处理海量大数据的秘籍
Hive Beeline 作为处理大数据的重要工具,在面对庞大的数据量时,如何高效应对是众多开发者关注的焦点。
Hive Beeline 处理大数据量并非易事,需要综合运用多种策略和技巧,首先要优化查询语句的编写,合理的查询语句能够显著提升数据处理的效率,避免使用全表扫描,而是根据具体需求添加合适的索引条件。

数据存储的格式选择也至关重要,采用合适的存储格式,如 Parquet 或 ORC,可以有效减少数据存储空间,提高读写性能。
在资源分配方面要做好规划,根据数据量和处理任务的复杂度,合理配置计算资源,包括内存、CPU 等,确保系统能够稳定运行。
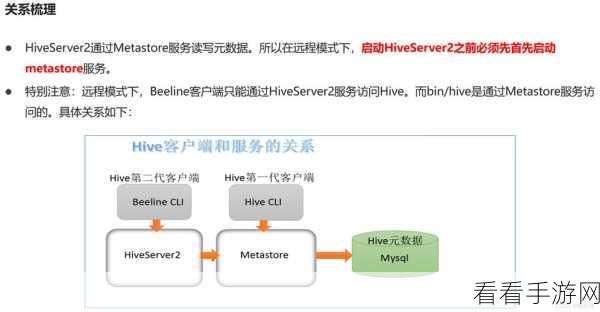
分区策略的运用能够大大提高数据处理的针对性,通过对数据按照特定的规则进行分区,可以快速定位和处理所需的数据子集。
对于频繁使用的数据,可以考虑建立缓存机制,以减少重复计算和数据读取的时间开销。
定期对系统进行性能监控和优化也是必不可少的,通过监控关键指标,及时发现潜在的性能瓶颈,并采取相应的优化措施。
掌握 Hive Beeline 处理大数据量的技巧,需要从多个方面综合考虑,不断实践和优化,才能在大数据处理的道路上更加得心应手。
文章参考来源:大数据处理相关技术文档及实践经验总结
