探寻 Hive row_number的性能瓶颈之谜
在大数据处理中,Hive 的 row_number() 函数常常被使用,但你是否知道它可能存在性能瓶颈?
Hive row_number() 函数在数据处理中扮演着重要角色,然而其性能问题却让许多开发者感到困扰,究竟是什么导致了这一性能瓶颈呢?
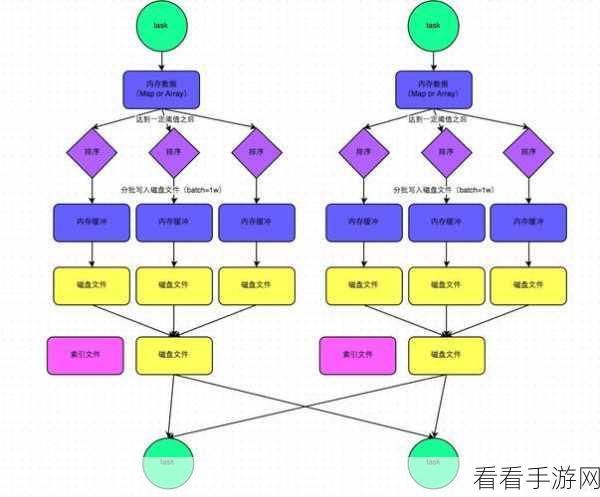
要深入理解 Hive row_number() 的性能瓶颈,我们需要从多个方面进行分析,数据量的大小是一个关键因素,当处理的数据规模庞大时,函数的执行效率可能会受到显著影响,查询语句的复杂程度也不容忽视,如果查询中包含了多个关联和嵌套操作,row_number() 函数的性能可能会进一步下降,Hive 的配置参数设置不当也可能成为性能瓶颈的原因之一。
为了优化 Hive row_number() 的性能,我们可以采取一些有效的措施,一是对数据进行合理的分区和分桶,这样可以减少数据扫描的范围,提高处理效率,二是优化查询语句的结构,尽量避免不必要的关联和复杂的计算,三是调整 Hive 的相关配置参数,例如内存设置、并行度等,以适应具体的业务需求。
在实际应用中,我们还可以通过一些案例来更好地理解和解决 Hive row_number() 的性能问题,某公司在处理大规模用户行为数据时,由于最初没有对数据进行合理分区,导致 row_number() 函数的执行时间过长,经过优化分区和查询语句后,性能得到了显著提升。
要解决 Hive row_number() 的性能瓶颈,需要我们综合考虑数据特点、查询语句和配置参数等多方面因素,并不断进行测试和优化。
参考来源:相关技术论坛及 Hive 官方文档。
仅供参考,您可以根据实际需求进行调整和修改。
