掌握 Hive 的 Split 处理复杂数据结构的关键技巧
在当今数据驱动的时代,处理复杂数据结构成为了许多开发者面临的重要挑战,Hive 作为一种强大的数据处理工具,其 Split 操作在应对复杂数据结构时有着独特的方法和技巧。
Hive 的 Split 操作对于处理复杂数据结构具有至关重要的作用,它能够将大规模的数据进行有效的分割和处理,提高数据处理的效率和准确性。
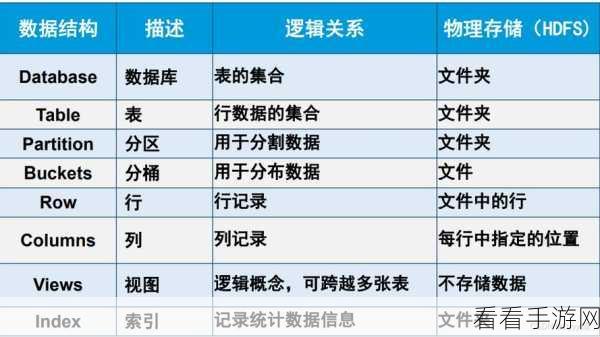
要理解 Hive 的 Split 如何处理复杂数据结构,我们需要先了解其基本原理,Split 操作基于特定的规则和算法,将数据按照一定的模式进行划分,这些规则可以根据数据的特征、分布以及处理需求来定制。
在实际应用中,合理设置 Split 的参数是关键,通过调整分割的粒度、分区的方式等,可以更好地适应不同的数据结构和处理场景,还需要考虑数据的一致性和完整性,确保分割后的结果符合预期。
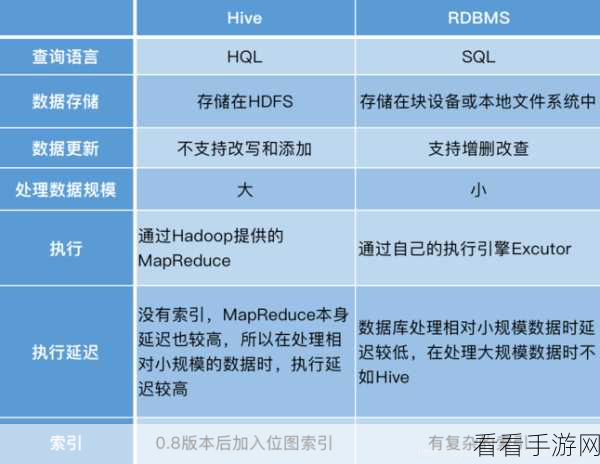
对于复杂的数据结构,可能需要结合其他 Hive 操作和函数来优化处理流程,使用特定的聚合函数、连接操作等,与 Split 相互配合,以达到更理想的数据处理效果。
为了确保 Split 操作的稳定性和可靠性,还需要对数据进行充分的预处理和清洗,去除无效数据、纠正错误格式等操作,可以减少在 Split 过程中出现的异常情况。
熟练掌握 Hive 的 Split 操作在处理复杂数据结构方面的技巧,对于提升数据处理能力和工作效率具有重要意义,需要不断地实践和探索,结合具体的业务需求,灵活运用各种方法和策略,才能充分发挥 Hive 的强大功能,实现高效的数据处理和分析。
文章参考来源:相关技术文档及实践经验总结。
