Python 分布爬虫的数据同步秘籍大揭秘
Python 分布爬虫在数据处理领域具有重要作用,而实现数据同步更是其中的关键环节。
分布爬虫的数据同步面临诸多挑战,不同节点之间的网络延迟、数据格式的一致性以及数据更新的实时性等,都是需要解决的难题。
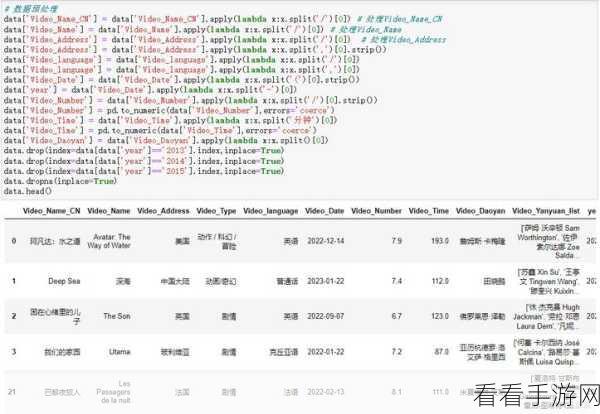
要实现 Python 分布爬虫的数据同步,首先得建立有效的通信机制,通过使用合适的网络协议和消息队列,确保各个爬虫节点能够及时交换数据和状态信息,可以采用 RabbitMQ 这样的消息中间件来实现高效的消息传递。
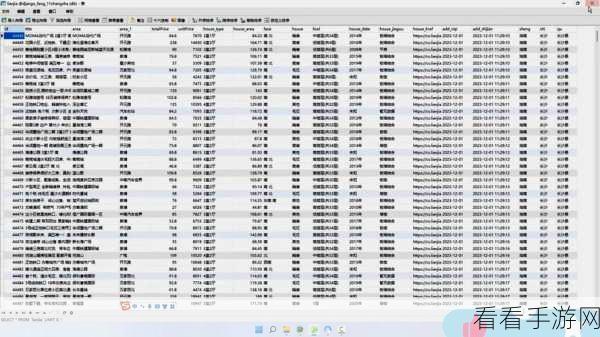
数据的存储和管理也至关重要,选择合适的数据库系统,并设计合理的数据结构,能够提高数据的存储和查询效率,使用分布式数据库如 MongoDB 或 Cassandra 可以更好地处理大规模的数据。
对于数据的一致性校验和错误处理要有完善的机制,在数据同步过程中,可能会出现数据丢失、重复或者错误的情况,通过引入校验算法和错误恢复策略,能够保证数据的准确性和完整性。
监控和优化也是不可或缺的环节,实时监控数据同步的状态和性能指标,根据反馈及时调整参数和策略,以达到最佳的同步效果。
Python 分布爬虫的数据同步并非易事,需要综合考虑多个方面的因素,并采用合适的技术和策略,只有这样,才能确保分布爬虫系统高效稳定地运行,获取到准确和有价值的数据。
参考来源:相关技术论坛及专业书籍。
仅供参考,您可以根据实际需求进行调整和修改。
