探秘 Hive 压缩表的数据压缩秘籍
Hive 压缩表的数据压缩是一个备受关注的技术问题,在大数据处理中,有效地压缩数据不仅能够节省存储空间,还能提升数据处理的效率。
要理解 Hive 压缩表的数据压缩,我们首先需要清楚数据压缩的基本原理,数据压缩的目的是通过去除数据中的冗余信息,以更少的存储空间来表示相同的数据量。
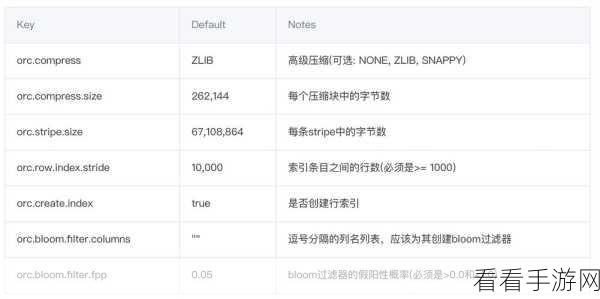
了解 Hive 支持的压缩算法至关重要,常见的压缩算法如 Gzip、Snappy 等,它们在压缩率和压缩解压速度上各有优劣,根据实际的数据特点和业务需求选择合适的压缩算法,是实现高效数据压缩的关键一步。
在实际操作中,配置正确的压缩参数也是必不可少的,设置压缩块的大小、压缩格式等,这些参数的调整会直接影响压缩效果和性能。
还需要考虑数据的访问模式,如果数据经常被读取和处理,那么在选择压缩算法和参数时,要兼顾压缩效率和解压速度,以保证数据处理的及时性。
Hive 压缩表的数据压缩并非一蹴而就,需要综合考虑数据特点、业务需求、压缩算法、参数配置以及数据访问模式等多个因素,通过不断的试验和优化,才能达到理想的压缩效果,提升数据处理的整体性能。
文章参考来源:大数据处理相关技术文档及实践经验总结。
