Hive 中 Split 处理大数据文件的秘籍指南
在当今的大数据时代,处理海量数据文件成为了许多企业和开发者面临的重要挑战,Hive 作为一种常用的数据仓库工具,其 Split 功能在处理大数据文件时发挥着关键作用,让我们深入探索 Hive 的 Split 是如何巧妙处理大数据文件的。
Hive 的 Split 功能旨在将大型数据文件分割成较小的部分,以便更高效地进行处理和分析,要实现这一目标,需要对数据的分布和特点有清晰的了解。
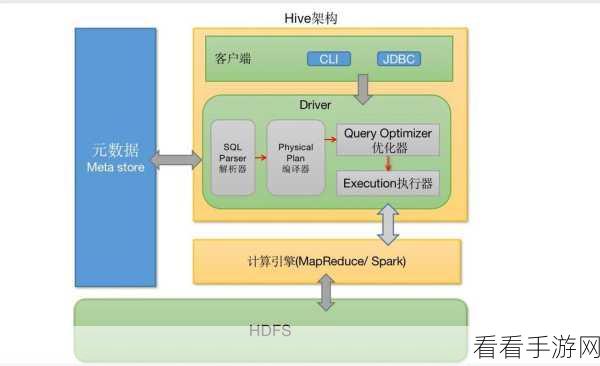
在确定如何使用 Split 之前,需要考虑数据的类型和规模,如果数据是结构化且规模巨大,可能需要采用特定的分割策略,以确保每个分割后的部分都能被高效处理。
对于非结构化的数据,Hive 的 Split 可能需要结合其他技术和工具来达到理想的处理效果,这可能包括数据清洗、转换等预处理步骤,为 Split 创造更好的条件。
配置合适的参数也是成功运用 Hive 的 Split 处理大数据文件的重要环节,调整分割块的大小、数量等参数,以适应不同的硬件环境和处理需求。
在实际应用中,还需要不断测试和优化 Split 的策略,通过观察处理结果、性能指标等,发现潜在的问题并进行改进。
熟练掌握 Hive 的 Split 处理大数据文件并非一蹴而就,需要综合考虑数据特点、配置参数、结合其他技术,并不断进行实践和优化,才能在大数据处理中取得出色的效果。
文章参考来源:Hive 官方文档及相关技术论坛的讨论。
