探索 Spark 在 Hive 中的独特优势,开启高效数据处理之旅
在当今数字化时代,数据处理的效率和质量至关重要,Hive 作为一种常用的数据仓库工具,而 Spark 在其中所展现出的优势成为了众多开发者和数据分析师关注的焦点,Spark 在 Hive 中究竟具有哪些显著的优势呢?
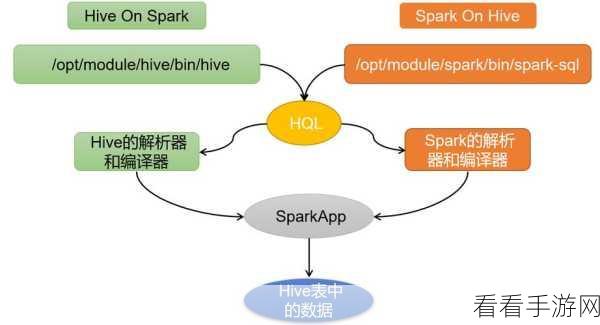
Spark 能够在 Hive 中展现出强大的优势,首先在于其出色的性能表现,Spark 基于内存计算的架构,使其在处理大规模数据时速度极快,能够大幅缩短数据处理的时间,相比传统的 Hive 处理方式,Spark 可以更高效地利用系统资源,实现快速的数据读取和计算。
Spark 具有丰富的编程接口和灵活的开发模式,它支持多种编程语言,如 Java、Python 和 Scala 等,让开发者能够根据自己的喜好和项目需求选择合适的语言进行开发,这种灵活性使得开发过程更加便捷,能够更好地满足不同应用场景的需求。
Spark 在 Hive 中的容错能力也值得称赞,在面对复杂的计算任务和可能出现的错误时,Spark 能够自动进行错误恢复和任务重试,确保数据处理的准确性和完整性,这一特性大大提高了系统的稳定性和可靠性,减少了因错误导致的数据丢失和处理中断的风险。
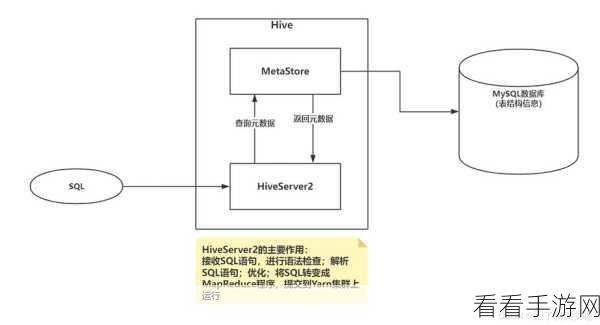
Spark 还支持与其他大数据技术的无缝集成,它可以与 Hadoop 生态系统中的其他组件,如 HBase、Kafka 等进行紧密结合,构建出功能强大、完整的数据处理流水线,这种集成能力为企业提供了更加全面和高效的数据解决方案,能够应对各种复杂的数据处理需求。
Spark 在 Hive 中的优势是多方面的,从性能提升到开发灵活性,再到容错能力和集成能力,都为数据处理带来了极大的便利和效率提升,深入了解和应用这些优势,将有助于开发者和企业在大数据领域取得更好的成果。
文章参考来源:大数据技术相关书籍及行业研究报告。
